
[知乎专栏经验发布] (https://www.zhihu.com/column/c_1760768090802171904)
距离上一篇”完结”过去了快一年,本来以为这个系列就这样了。
然后 AI 来了。
不是那种”帮你补全几行代码”的 AI,而是真的能从零开始、一个文件一个文件帮你写出来的 AI。看着 Claude 一步步理解我的需求,读懂 VNPY 的源码,处理 PySide6 的信号槽、QSS 样式、Pydantic 数据模型……说实话,有点震撼。
于是趁着春节前的这段时间,我做了一个实验:用 AI 辅助,从 VNPY 3.9 重构到 4.3,看看能走多远。
结果是:大约一周时间,从项目搭建到功能完善,我没有手写一行代码。所有的代码都是在和 AI 的对话中产生的——我负责提需求、审代码、做决策,AI 负责实现。
为什么要重构
VNPY 从 3.9 到 4.3 变化很大,核心模块拆分成了独立包(vnpy-ctastrategy、vnpy-ctp 等),架构上差异太多,简单迁移行不通,不如重新来过。
正好,V1 积累了不少想法但一直没动手改的地方,这次借 AI 之手一并实现了。
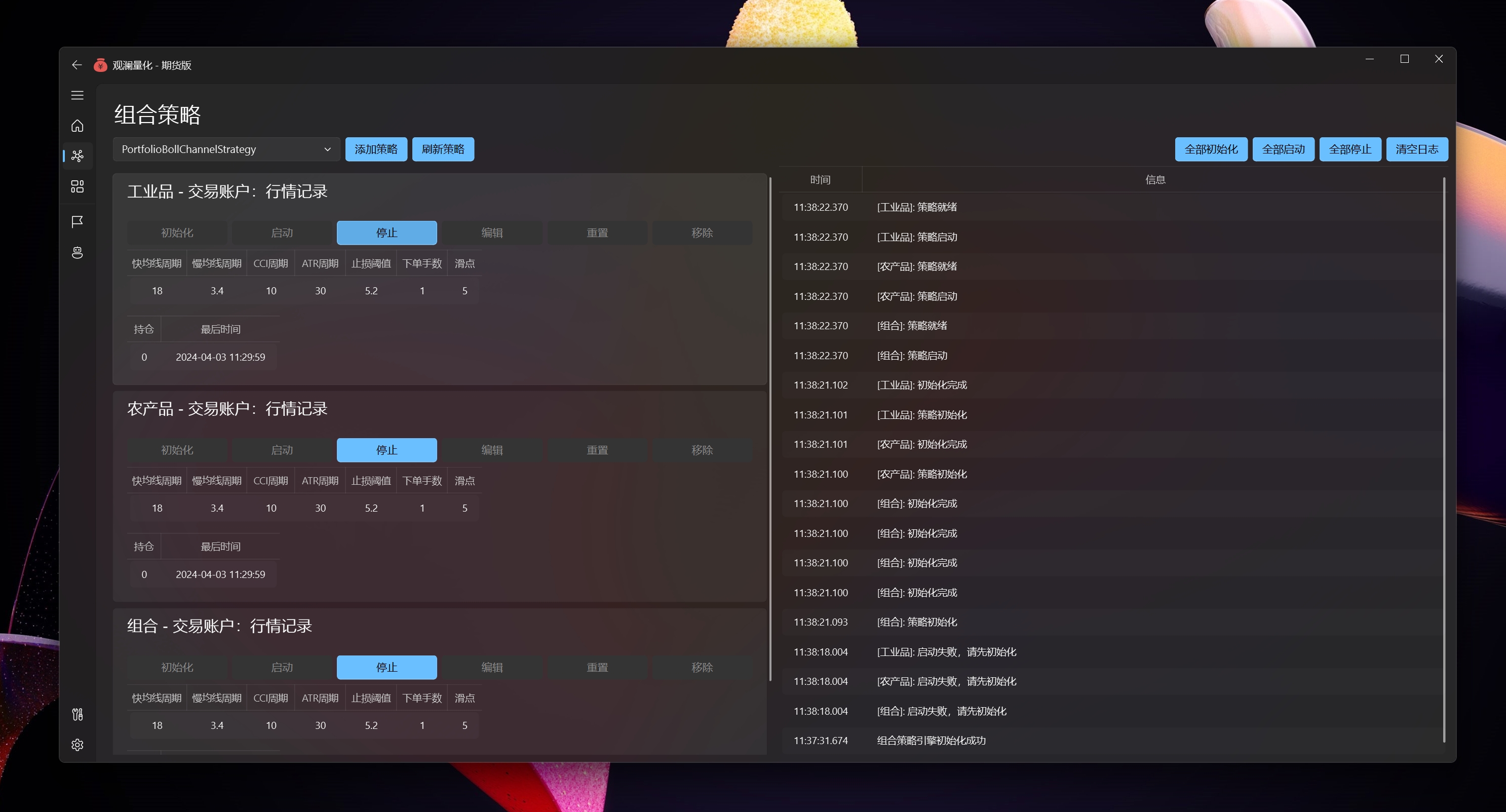
V2 主要变化
变化 说明
基础框架 VNPY 3.9 → 4.3
数据库 SQLite/MySQL → ArcticDB (LMDB)
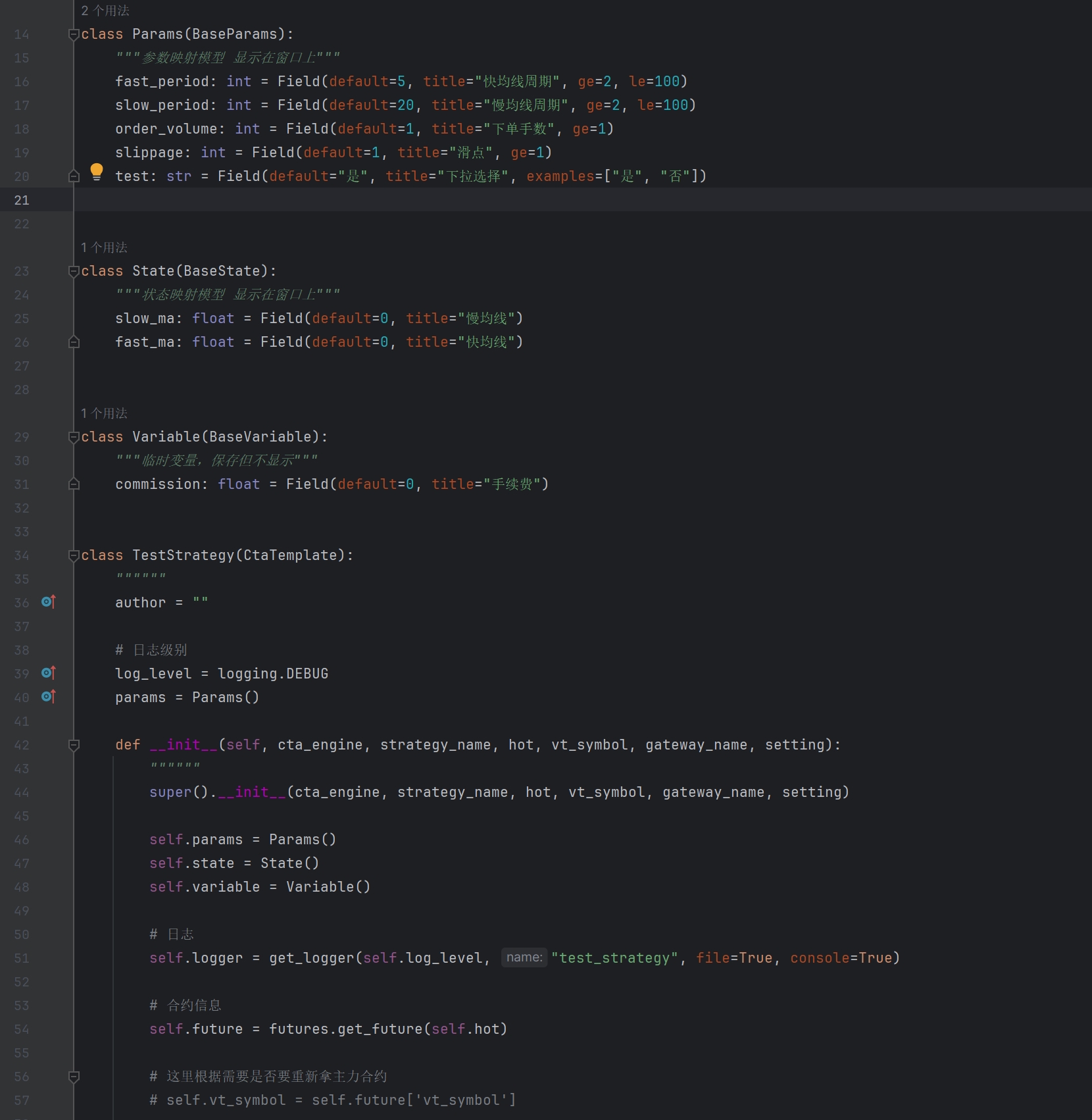
策略架构 三层数据模型 Params/State/Vars
双模交易 同一策略支持全自动 + 辅助半自动
多账户 实盘/模拟/7×24 环境并存
主力合约 自动识别 + 换月持仓保护
AI 助手 实验性接入,目标是策略信号辅助
界面 PySide6 + QFluentWidgets 全面重写
详细内容就不在这里展开了,感兴趣的朋友请移步 GitHub 仓库查看 README。
开源
项目已开源,MIT 协议,可自由使用和修改:
GitHub:https://github.com/48645970/guanlan
欢迎 Star,欢迎提 Issue,欢迎交流。
感谢
感谢 VNPY 团队提供了优秀的量化交易框架,让这一切有了基础。
感谢 Claude —— 这个项目的”联合开发者”。一周时间里,从框架搭建到细节打磨,每一行代码都经过了我们之间的对话。AI 不会疲倦,不会敷衍,能记住上下文,能读懂源码,能理解”这里不太对”是什么意思。这种体验,一年前完全无法想象。
我们正站在一个很有意思的时代节点上。
最后
祝大家新年快乐,交易顺利。
主窗口
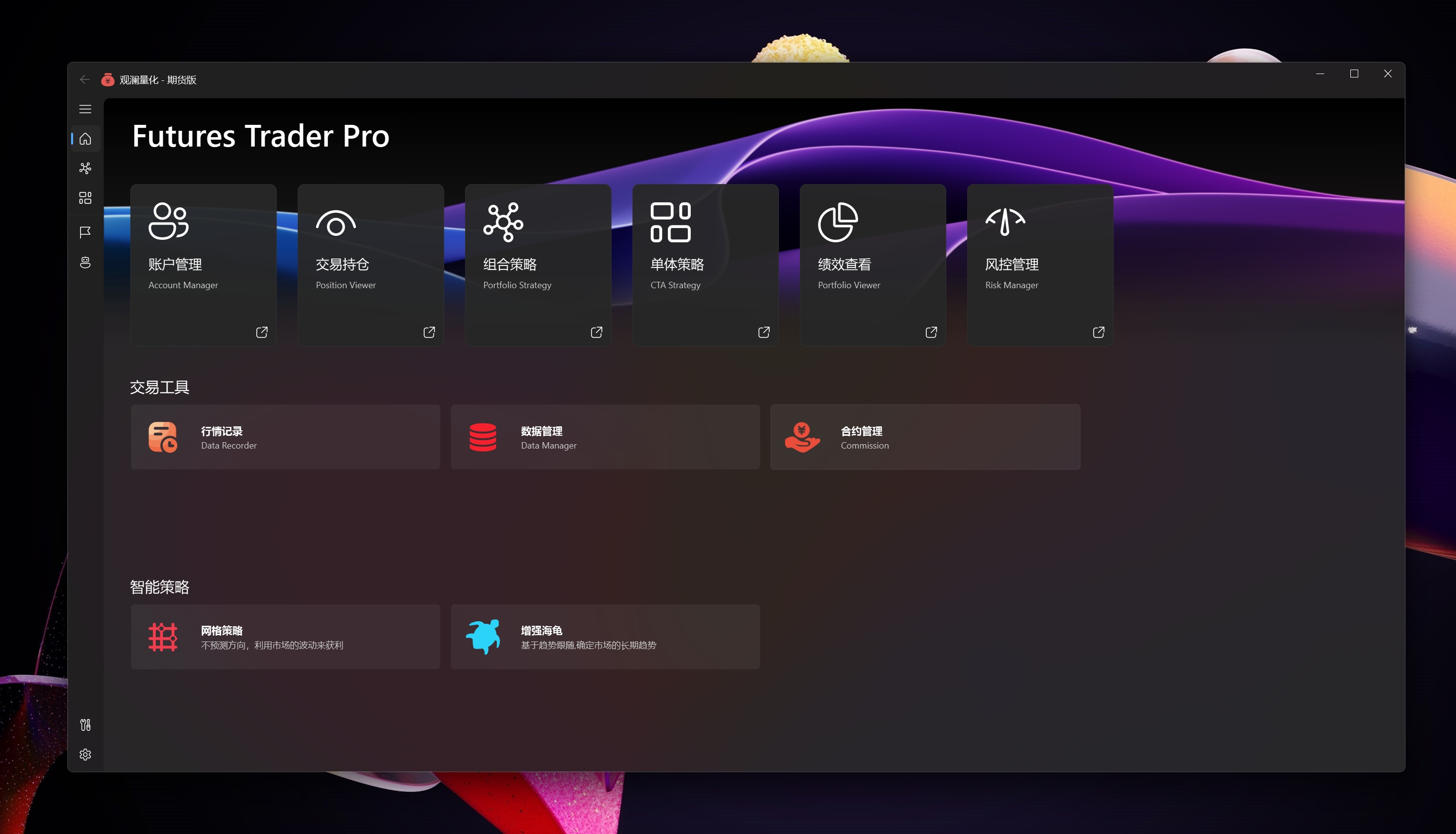
多账户管理,自动登录
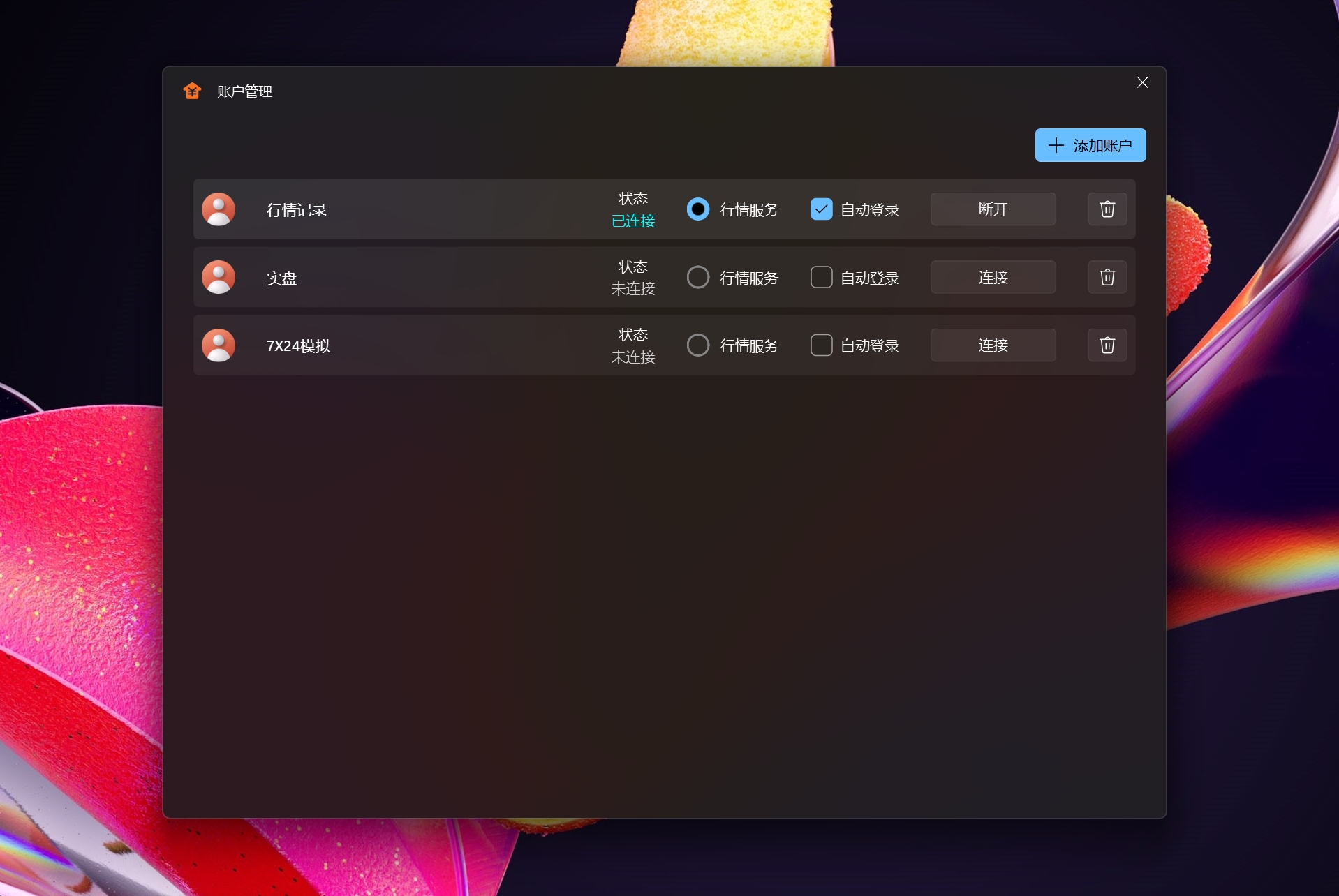
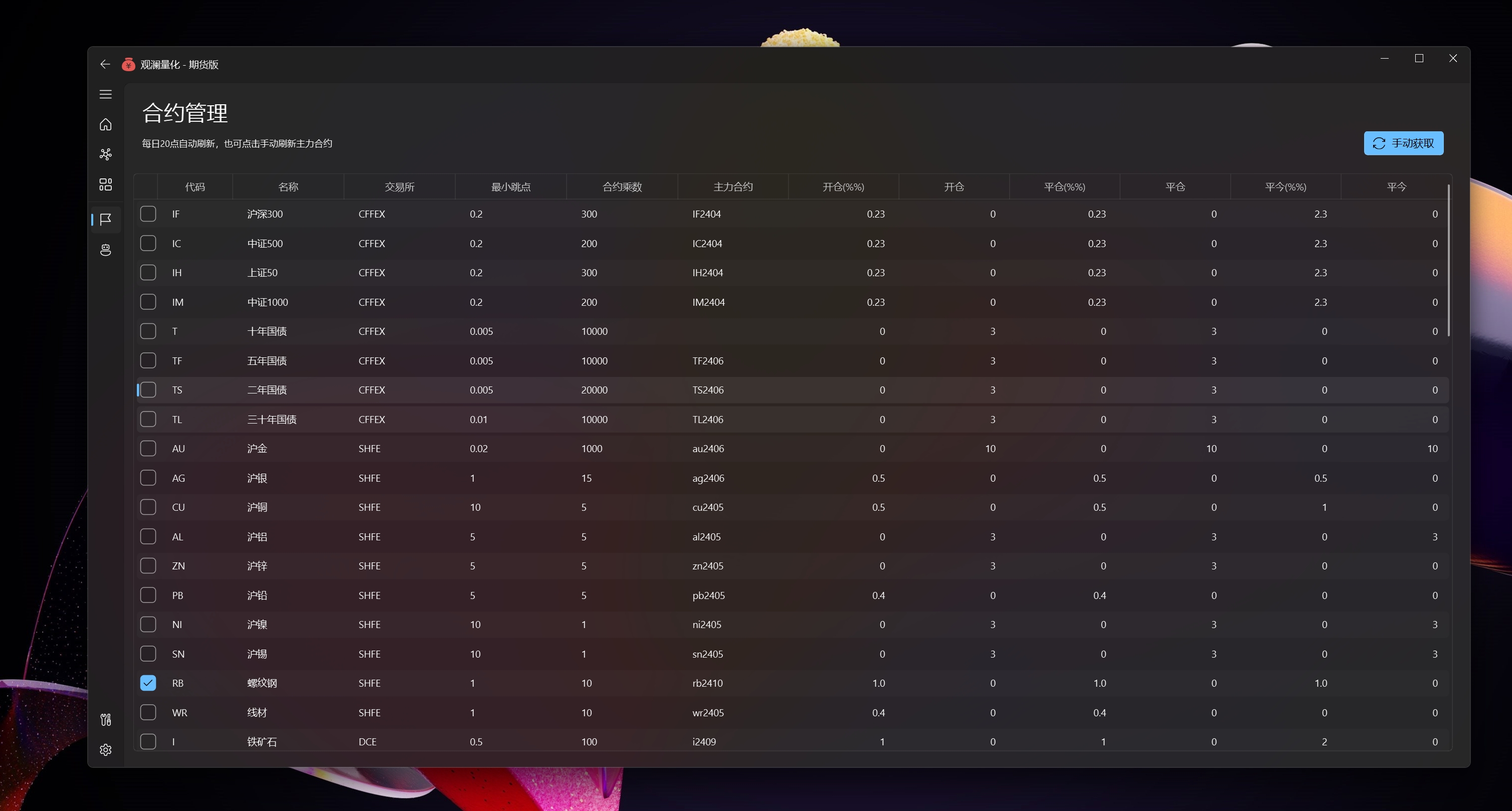
合约管理,收藏,手续费设置(策略中算手续费),定期从外部获取后计算最大持仓定为主力
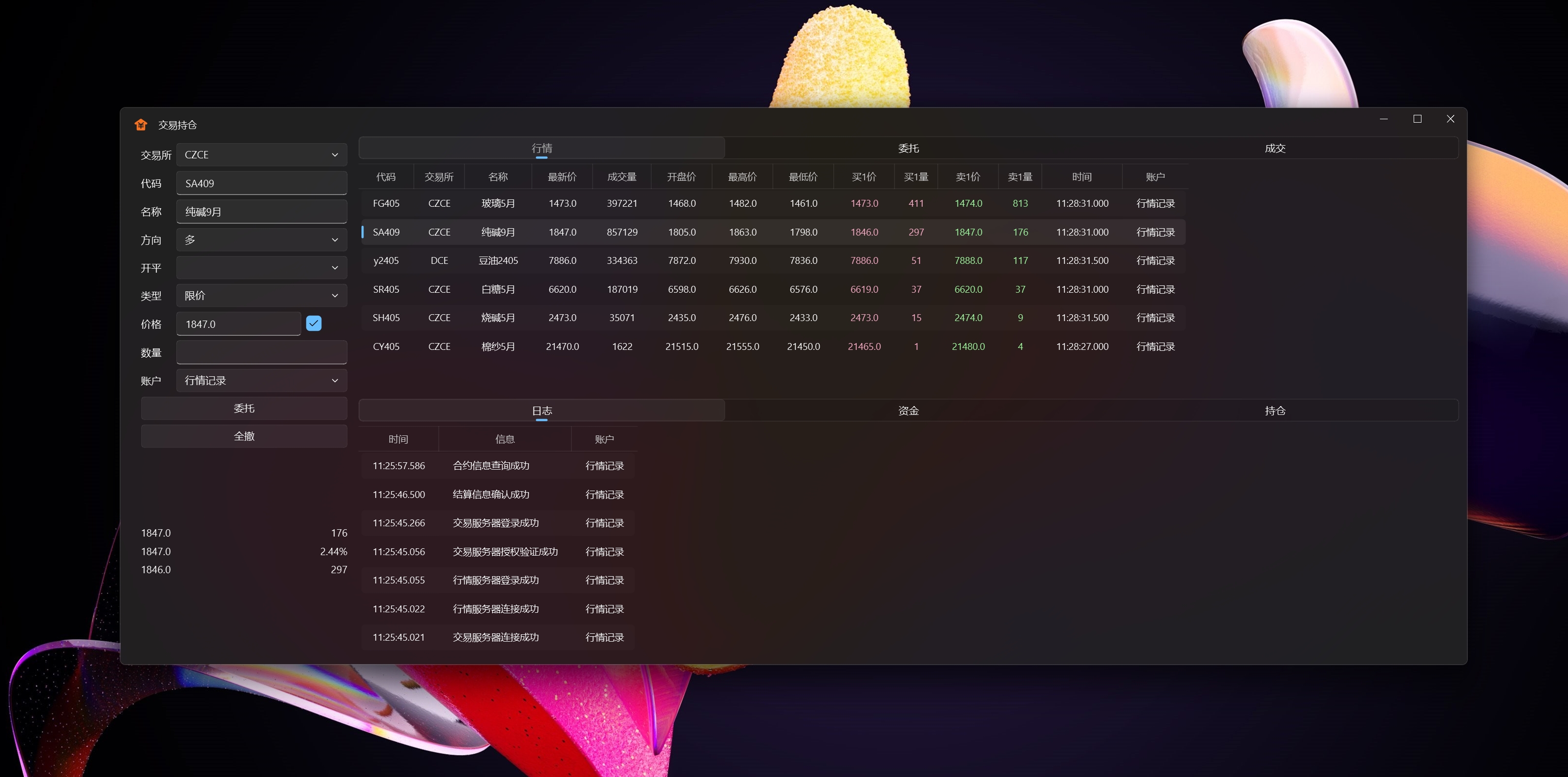
交易持仓
绩效查看,按账户统计
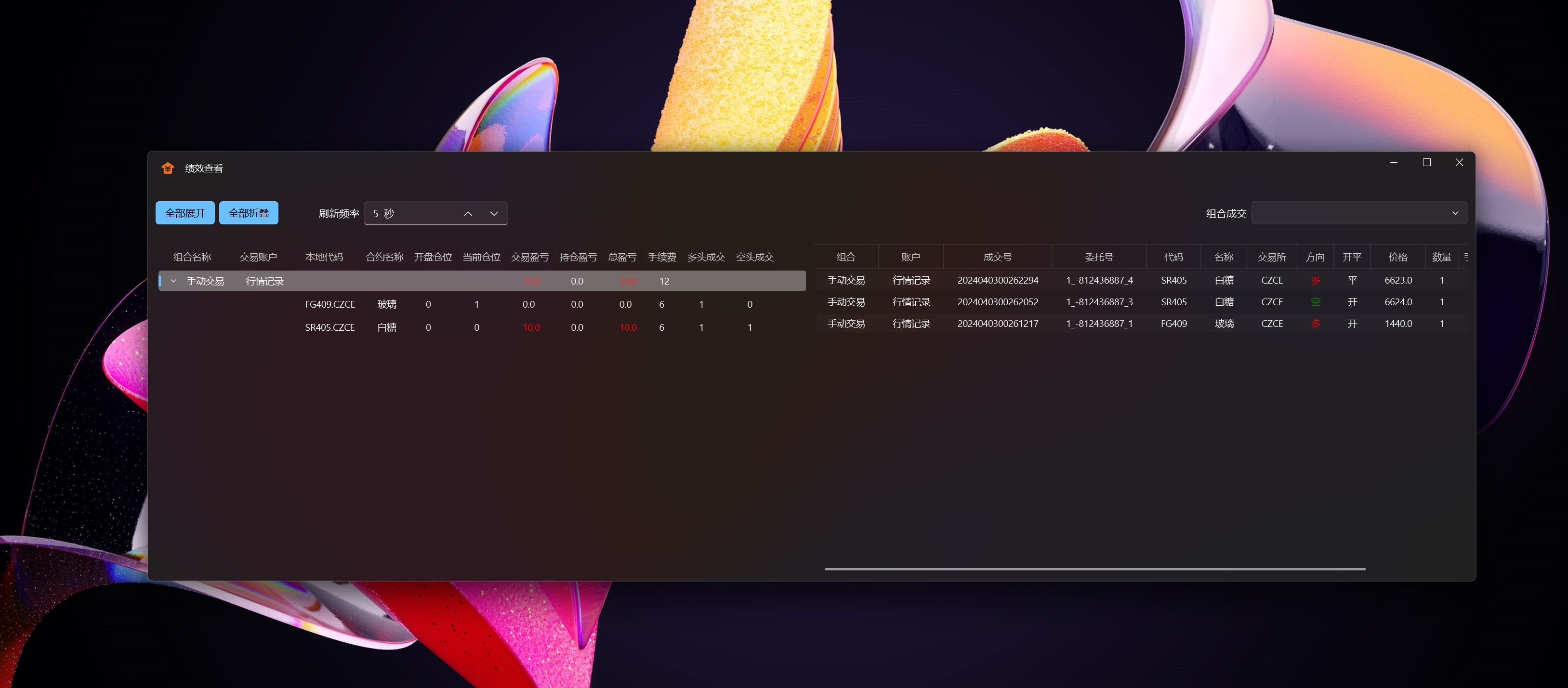
数据管理,一键批量导入通达信数据(日线、分钟线)

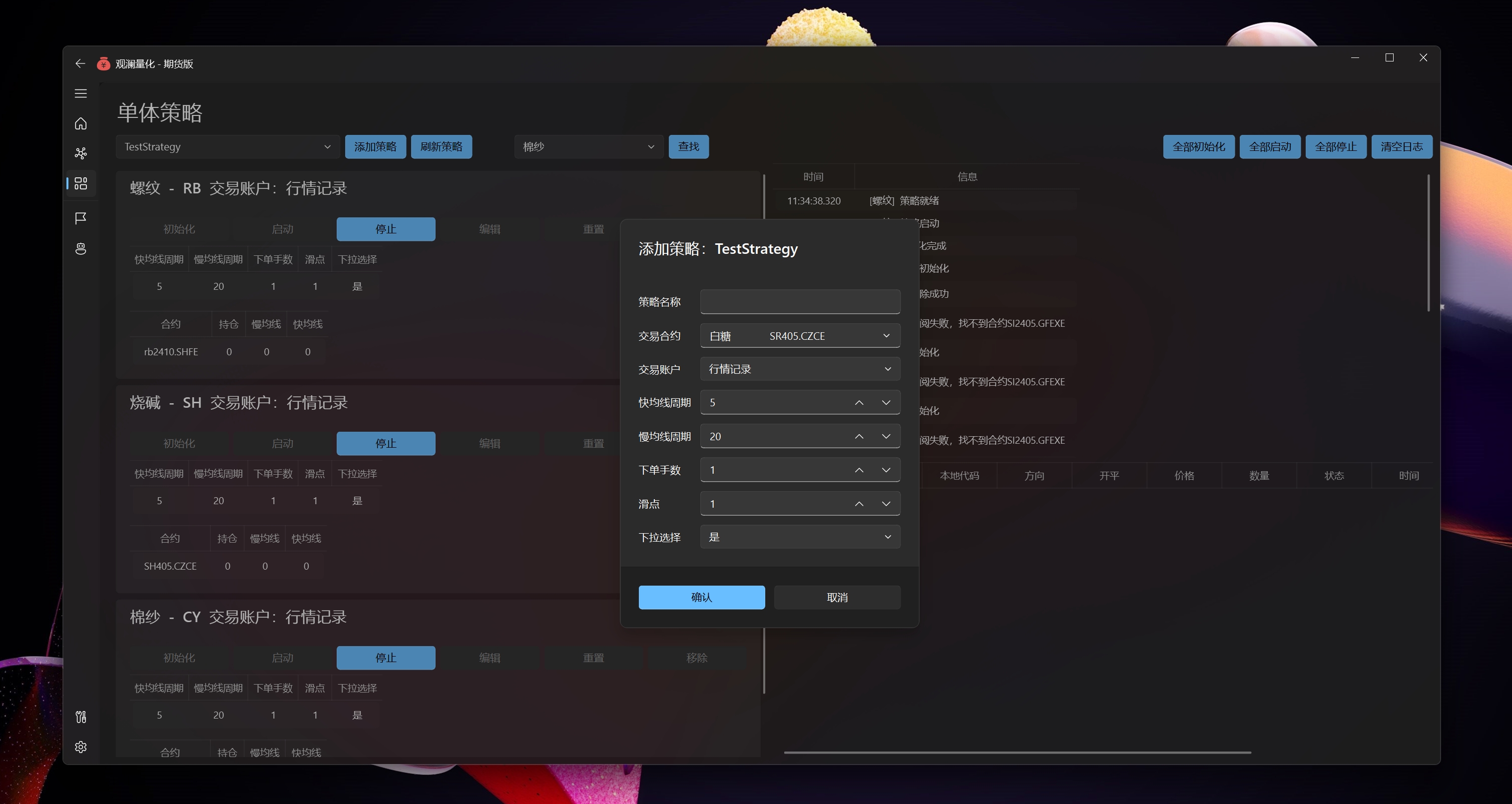
策略执行
使用数据模拟定义参数和状态显示,配合限制输入框,对输入内容格式、最大最小值做限制
界面参数、状态值,使用模型指定的中文标题显示
Params、State 显示在窗口
Variable 仅做为中间变量存储,但不显示
扩展 on_ready,在在 on_start 后触发,不同的是,交易状态 self.trading == True
扩展 on_reset,在画面点击重置时触发
发布于VeighNa社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2025-12-29
上周我们发布了VeighNa 4.3.0版本。本次更新主要包括:在VeighNa Station中集成全新的AI智能助手VeighNa Assistant,以及对VeighNa Docker镜像进行重构优化。
已安装VeighNa Studio 4.0版本的用户,可使用快速更新功能完成自动升级;尚未安装的用户,建议直接下载VeighNa Studio-4.3.0,体验一键安装的量化交易Python发行版,下载链接:
https://download.vnpy.com/veighna_studio-4.3.0.exe
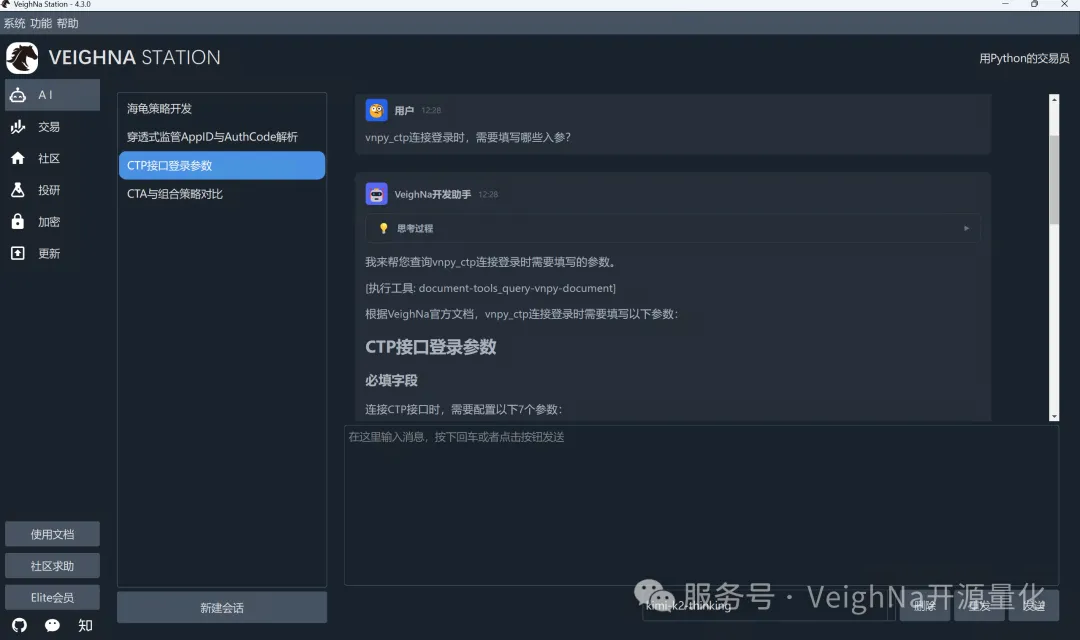
在本次4.3.0版本中,VeighNa Station集成了VeighNa Assistant智能助手(基于VNAG框架开发),主要功能包括:
要使用VeighNa Assistant,首先需要准备一个大模型服务的API Key(可理解为访问凭证)。对于初次接触的用户,推荐使用阿里云百炼的AI服务(目前提供较为充足的免费额度),具体开通流程请参考阿里云官方的详细步骤说明。
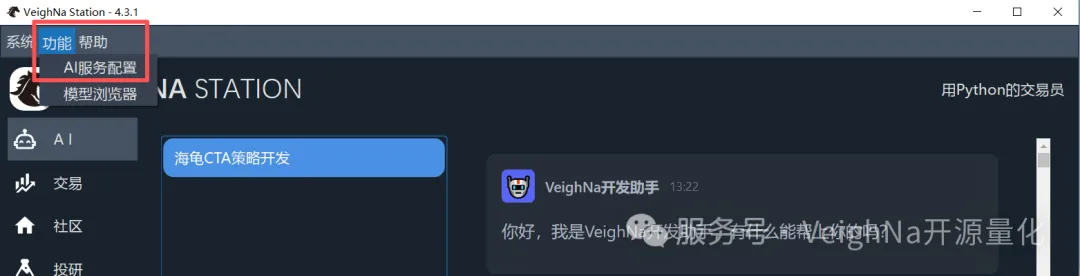
准备好API Key后,双击桌面快捷方式启动VeighNa Station,在顶部菜单栏中找到【功能 -> AI服务配置】选项:
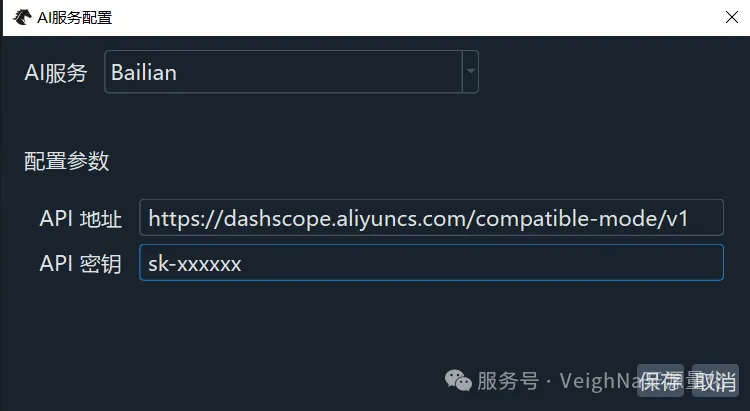
点击后将打开AI服务配置对话框。在顶部的下拉框中选择【Bailian】,然后在配置参数区域填入之前准备好的API Key,API地址保持默认即可:
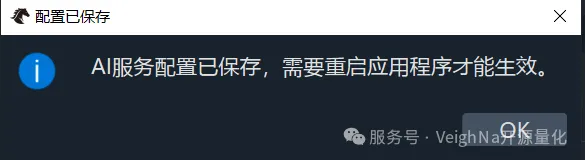
点击【保存】按钮后,系统会弹出提示框,告知需要重启VeighNa Station以使配置生效:
完成重启后,点击顶部菜单栏的【功能 -> 模型浏览器】,选择想要使用的大模型:
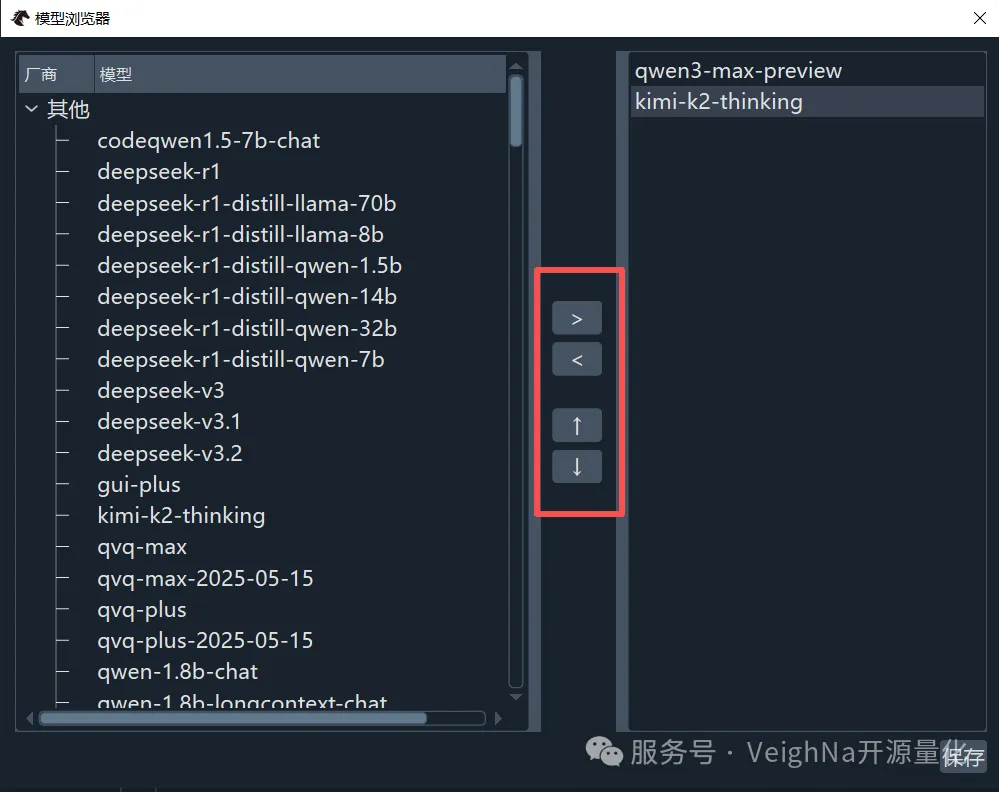
在模型浏览器中,可以通过上图红框中的箭头按钮来添加或移除大模型,同时也可以调整已选模型的优先级顺序。对于百炼AI服务,推荐选择Agentic能力较强的qwen3-max-preview或kimi-k2-thinking模型。完成设置后,点击右下角的【保存】按钮,系统会弹出确认提示框:
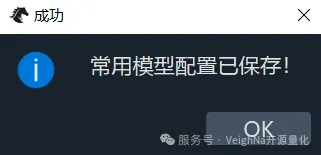
点击【OK】返回主界面后,即可在聊天区域与智能体进行交互。整体使用方式与ChatGPT等主流AI聊天工具高度相似,有相关使用经验的用户可以快速上手:
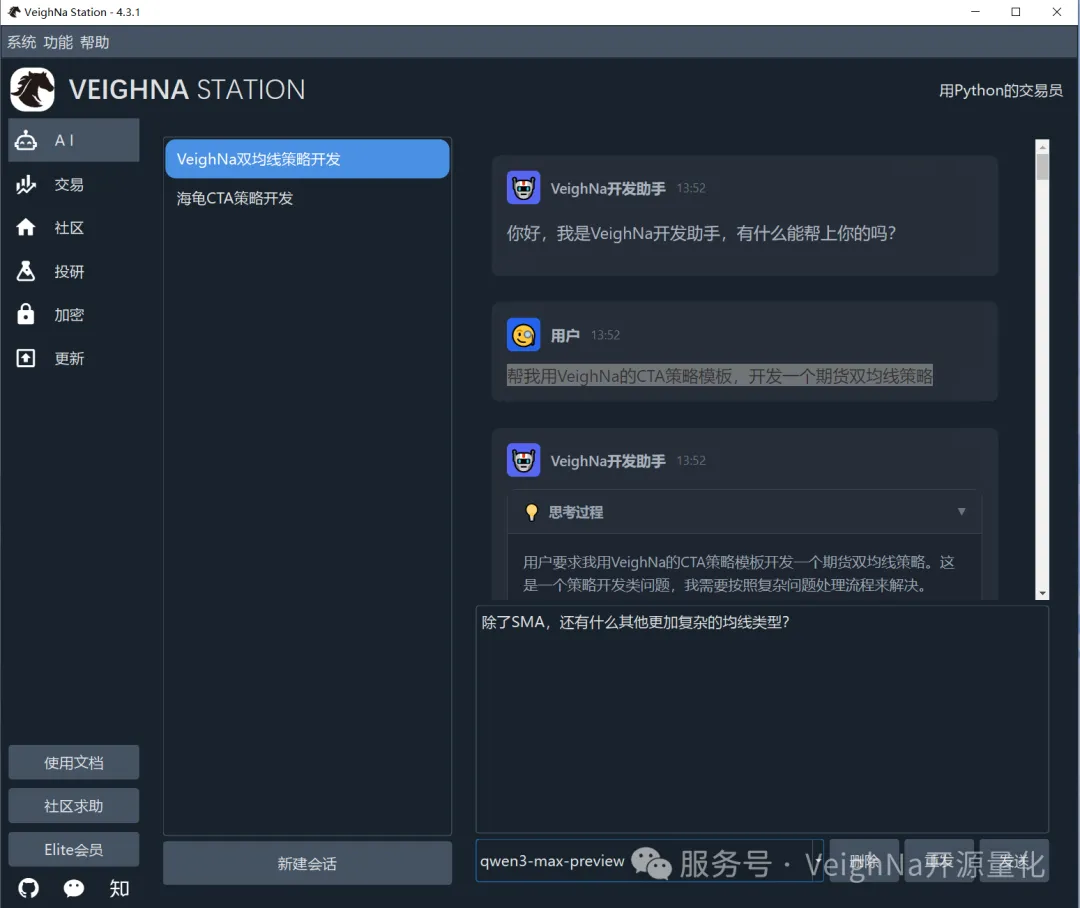
如果在使用过程中遇到任何问题或有改进建议,欢迎在社区论坛的【VeighNa Assistant】专区发帖交流。
基于社区用户的反馈,我们在4.3.0版本中 对VeighNa Docker镜像进行了全方位的重构与优化。
核心改进:
快速开始:
用户可以直接访问VeighNa Docker Hub查看详情,或使用以下命令直接拉取并启动:
# 拉取 4.3.0 版本镜像
docker pull veighna/veighna:4.3.0
# 启动容器(示例:挂载本地目录并启动图形界面)
docker run -it \
-e DISPLAY=$DISPLAY \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v $(pwd)/home:/home \
-p 8888:8888 \
veighna/veighna:4.3.0 python3 -m veighna_station
新增
调整
修复
安装流程:
打开terminal-注意环境切换成 py37_vnpy,执行以下命令,安装需要的插件
pip install -r requirements.txt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com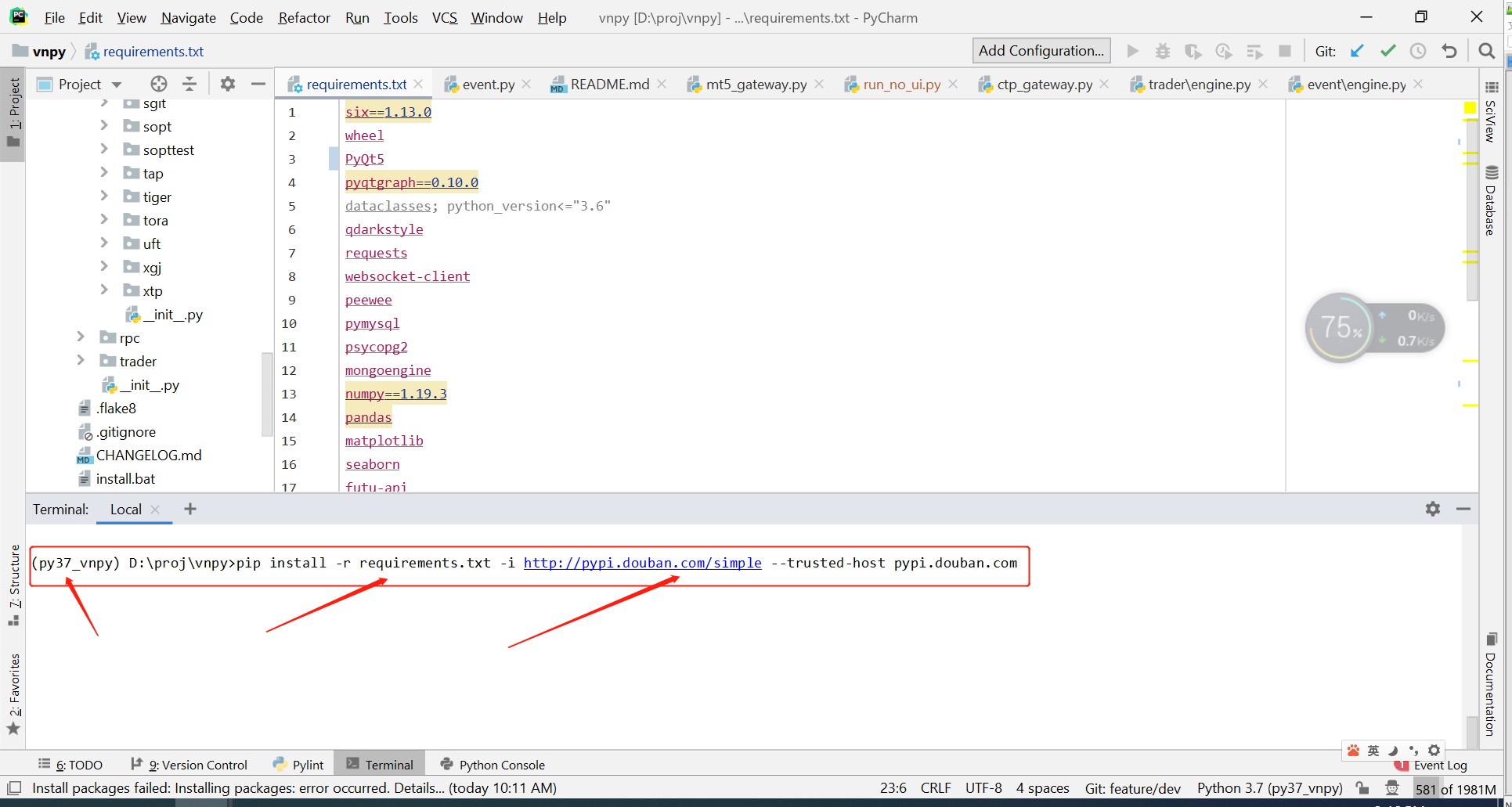
遇到安装失败的可以单独安装:
pip install PyQt5 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com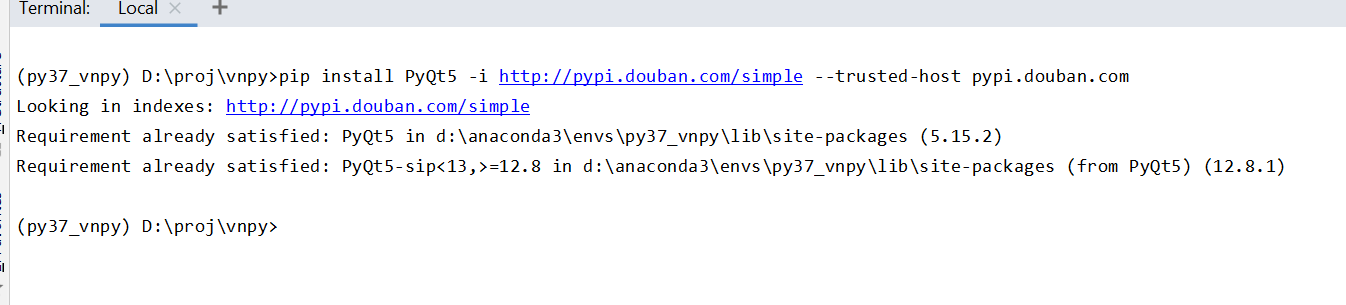
备注:
如果需要在cmd 下使用 py37_vnpy 环境。
打开 CMD
运行: conda activate py37_vnpy
会切换到py37_vnpy环境下
作为初学者,面对 vnpy 无所不包、博大精深的丰富内容,试图用图形对 vnpy 的运行流程做一个归纳。
不到之处,还请各位多多指正

我原本想用WSL2在windows机器上启动一个ubuntu机器来运行vnpy,因为期货公司不让用云服务器或者虚拟机进行测试,所以我同时安装了windows,也把Windows和Ubuntu两种环境的坑都踩了。。。
在windows/mac/linux环境中,windows不许需要环境准备,直接下载安装包就行。我使用ubuntu属于linux。
其他回答普遍反映install.sh有问题,我试了一下,确实有问题。于是直接手动安装。说是手动安装其实也快。
# 下载vnpy到ubuntu本地
git clone git@github.com:vnpy/vnpy.git下面开始配置环境,我使用的pyenv+venv轻量化的环境配置方案。
pyenv功能:为不同项目提供不同的python版本。比如我A项目使用3.7.4, 而vnpy推荐使用3.13版本。使用了pyenv我就可以实现在A项目用3.7.4,在vnpy使用3.13,而不是两个系统使用同一个版本的python。
venv功能:为不同项目提供不同的依赖。A项目使用了2.27.1版本的requests包,而vnpy使用3.0.01版本的requests包(其实没有),直接使用pip install只能同时安装一个包,使用venv就可以把A项目和vnpy项目依赖的包隔离开了。
其他教程里面的conda,minicoda其实都是实现pyenv+venv的功能,选择使用conda还是pyenv+venv区别不大。
# 安装pyenv
curl https://pyenv.run | bash
# 查看可安装的 Python 版本
pyenv install --list
# 安装指定版本
pyenv install 3.13.2
# 查看已安装的版本
pyenv versions
# * system (当前使用的版本)
# 3.8.10
# 3.11.0
# 2. 本地(当前目录及子目录)
cd vnpy
pyenv local 3.13.2 # 该项目使用 3.13.2
# 会自动创建 .python-version 文件,此时在vnpy项目下运行python --version就会提示版本信息为3.13.2
# 创建venv虚拟环境
python3 -m venv .venv
# 激活虚拟环境
source .venv/bin/activate
# 安装vnpy的依赖包
pip install .# 安装build-essential
sudo apt-get install build-essential
# 安装ta-lib
wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz
tar -zxvf ta-lib-0.4.0-src.tar.gz
cd ta-lib/
./configure --prefix=/usr
make
sudo make install
pip install ta-lib
# 我并没有确认下面两个是否必须,直接按照其他教程安装了
pip install quickfix
pip install psycopg2-binary在examples/veighna_trader/run.py有个run.py文件,将它复制到vnpy的根目录下。在vnpy目录,运行python run.py
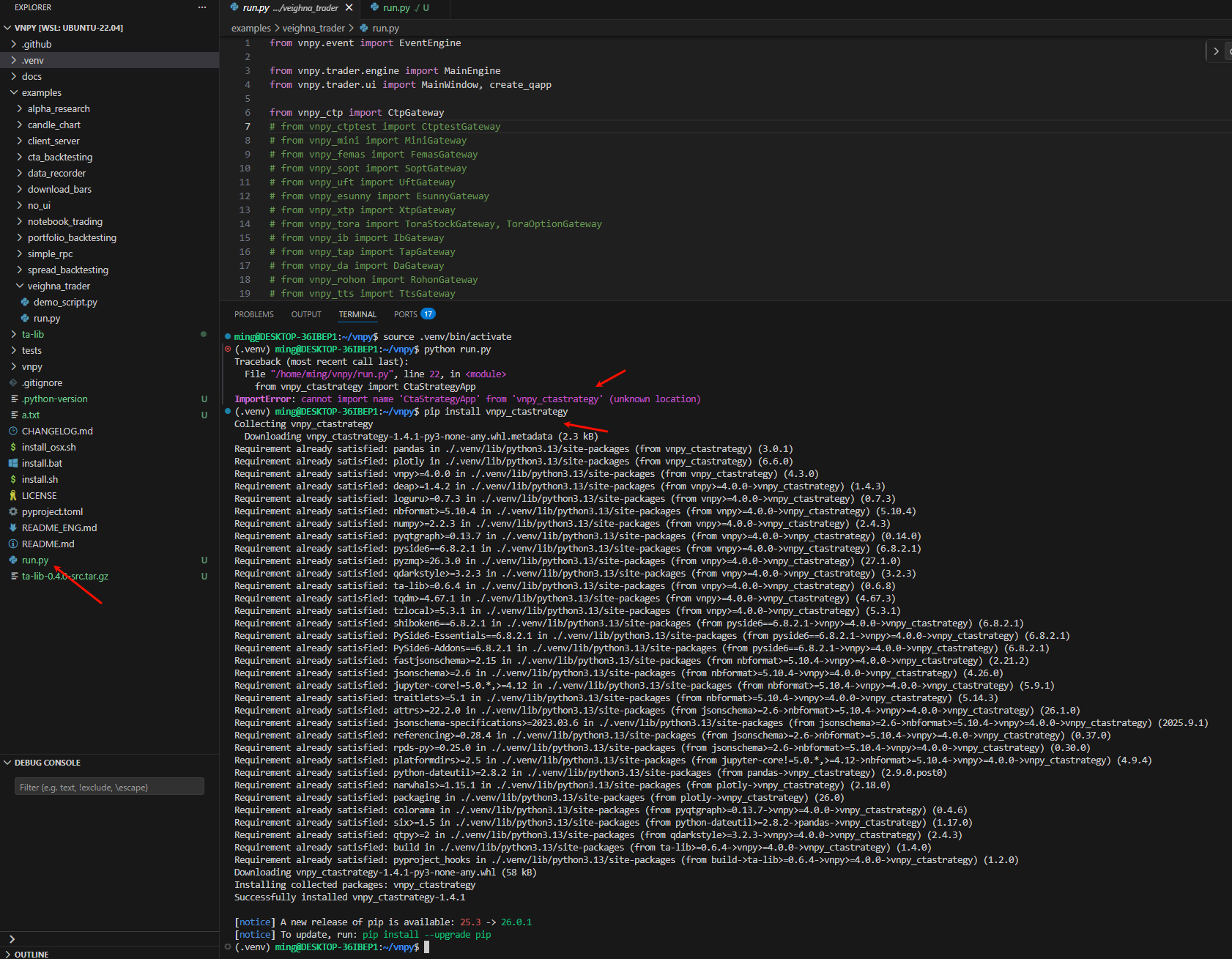
这时候可能会报“'CtaStrategyApp' from 'vnpy_ctastrategy' (unknown location)”,很简单,只要安装这个模块就行,比如这个vnpy_ctastrategy,使用pip install vnpy_ctastrategy命令即可。
然后运行python run.py,就可以打开vnpy界面。如果没有打开,很有可能是没有GUI,如果是没有GUI的话,可以看下面。
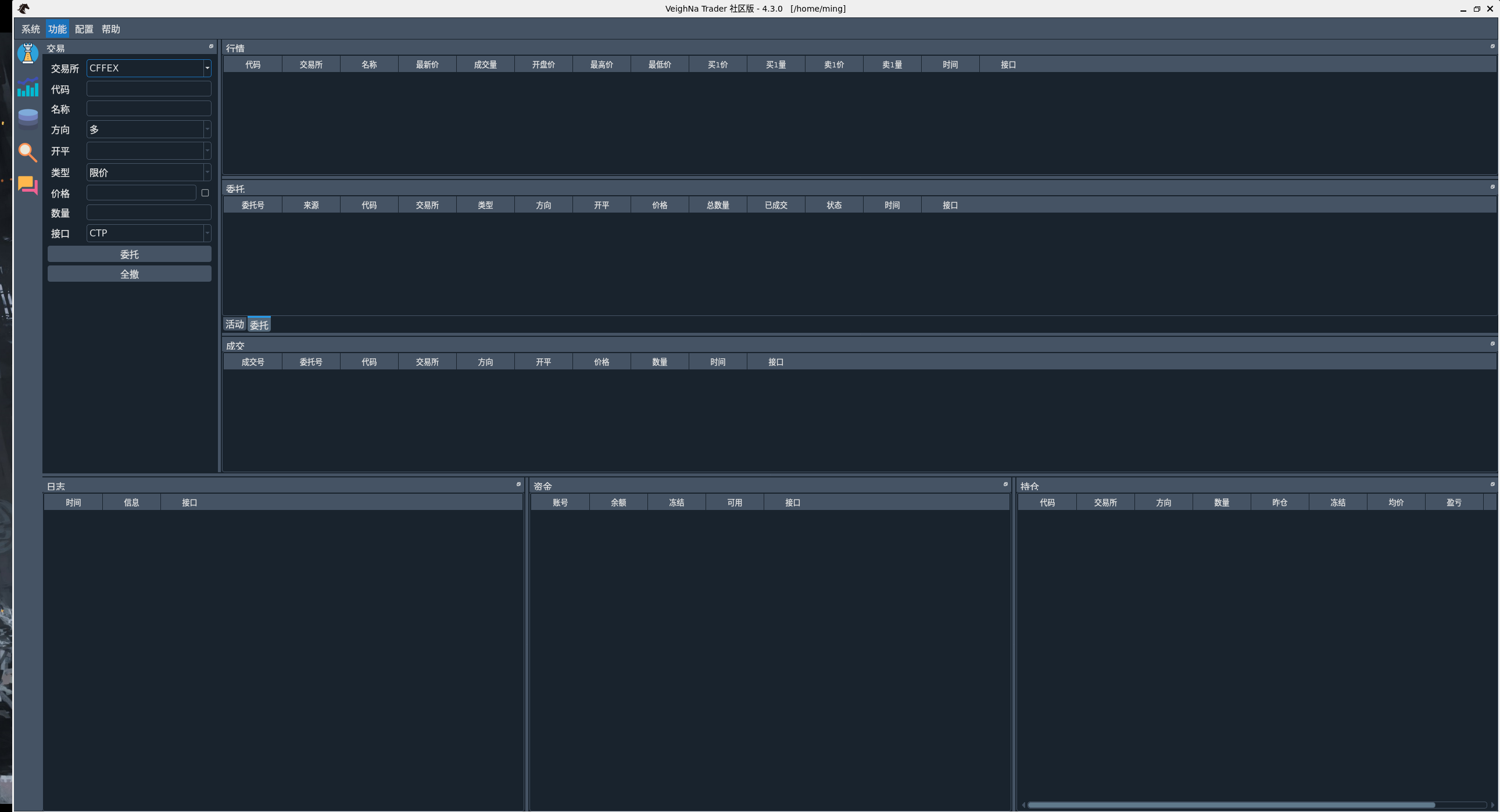
如果是使用没有界面的ubuntu,比如我使用WSL,是不能装xubuntu-desktop太重的界面的。如果是win11可以使用WSLg,我的是win10,用的X410。AI给的完整UI配置流程我也放下面了。
去SimNow仿真交易【官方网站】官网注册一个账号,注册账号后,找到官网通知公告内的BrokeID,Trade Front,Market Front
SimNow仿真交易-产品与服务。左侧“产品和服务”打不开的话,先打开官网,然后点击顶部导航栏的“产品与服务”,下拉到中间就有simnow的链接配置信息。
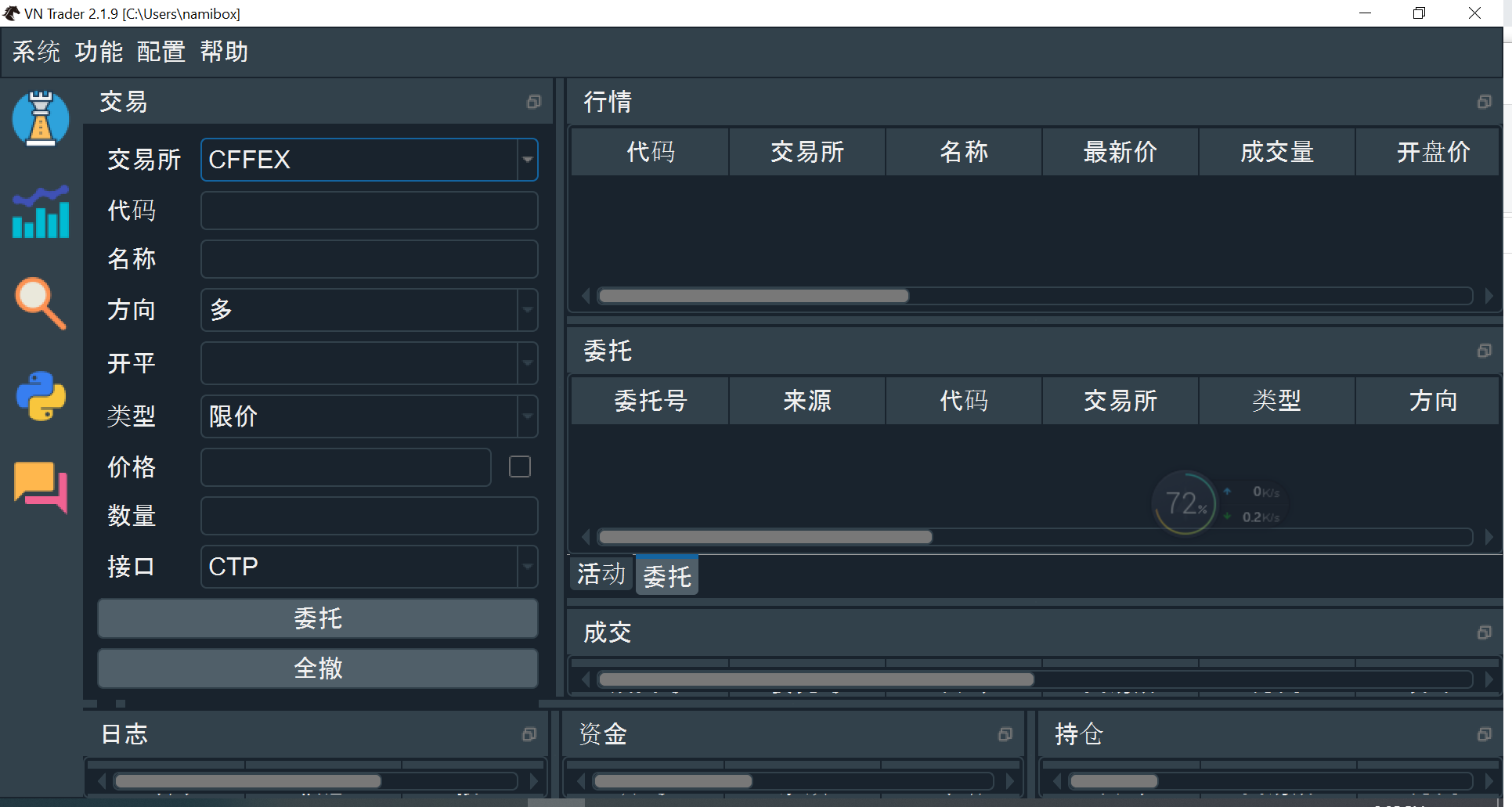
在vnpy界面中,点击系统->连接CPT,然后按照下图所示的配置填写。其中
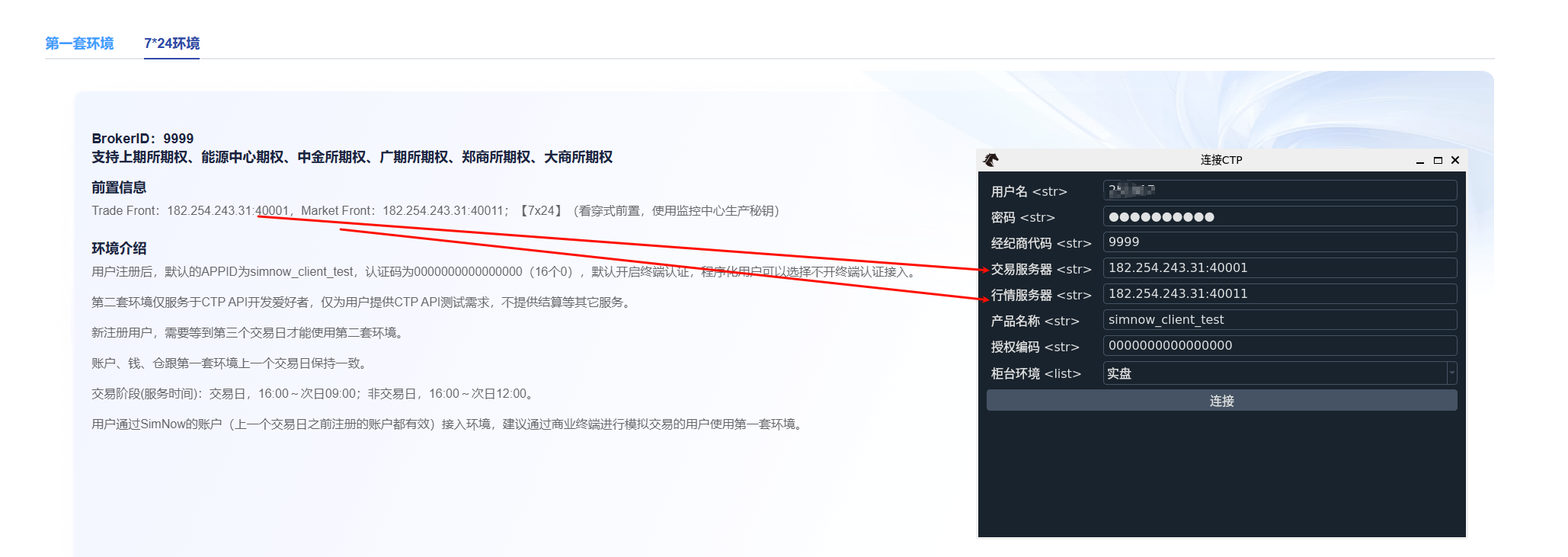
登录成功后,可以点击帮助->查询合约->查询,来看合约信息是否有,有就成功了。
后面的穿透测试流程以及window,linux环境下decode err的解决方法我都写在这里了。https://www.vnpy.com/forum/topic/34604
经过好几天的反复,终于完成了。所谓的复盘,就是盘后把行情从新播放一遍,如果使用tick数据,就和真实的盘面一模一样,我这里使用的是1分钟数据复盘,所以简化了很多。
代码如下:
import multiprocessing
import time
from datetime import datetime
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.database import database_manager
from vnpy.chart import ChartWidget, VolumeItem, CandleItem
from vnpy.trader.ui import create_qapp, QtCore
from vnpy.trader.object import BarData
import os
bar: BarData
def putbardata(q_1m,q_5m,q_30m,q_4h,su):
#从数据库中读取1分钟数据,你的数据库必须有下载好的数据。
bars = database_manager.load_bar_data(
symbol="APEUSDT",
exchange=Exchange.BINANCE,
interval=Interval.MINUTE,
start=datetime(2022, 5, 4),
end=datetime(2025, 1, 1)
)
sudu = 0.055
i = 0
for bar in bars:
q_1m.put(bar)
q_5m.put(bar)
q_30m.put(bar)
q_4h.put(bar)
if i > 1200: #先快速播放一定数量的一分钟bar
if not su.empty():
sudu = int(su.get(True))
print("速度已经设定为:", sudu)
if i % 10 == 1 :
os.system("pause") #正常播放以后,每10个一分钟bar暂停一下,按任意键继续,不需要这个功能的可以删掉。
time.sleep(sudu)
i = i + 1
def MINUTE_5m(q):
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history : BarData
history = []
global i_5
i_5 = 0
global bar_
def update_bar():
global i_5
global bar_
if not q.empty():
bar = q.get(True)
if i_5 == 0 :
bar_ = bar
i_5 = 1
history.append(bar_)
if i_5 == 5 :
bar_ = bar
i_5 = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_5 = i_5 + 1
history[-1] = bar_ #这一段是把一分钟数据形成5分钟数据
widget.clear_all()
widget.update_history(history) #刷新图形数据
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("五分钟") #设定五分钟窗口的标题和窗口大小以及位置
widget.setGeometry(0, 0, 900, 550)
widget.show()
app.exec_()
def MINUTE_30m(q): #30分钟和5分钟类似
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history: BarData
history = []
global i_30
i_30 = 0
global bar_
def update_bar():
global i_30
global bar_
if not q.empty():
bar = q.get(True)
if i_30 == 0 :
bar_ = bar
i_30 = 1
history.append(bar_)
if i_30 == 30 :
bar_ = bar
i_30 = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_30 = i_30 + 1
history[-1] = bar_
widget.clear_all()
widget.update_history(history)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("三十分钟")
widget.setGeometry(0, 560, 900, 550)
widget.show()
app.exec_()
def MINUTE_4h(q):
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history: BarData
history = []
global i_4h
i_4h = 0
global bar_
def update_bar():
global i_4h
global bar_
if not q.empty():
bar = q.get(True)
if i_4h == 0 :
bar_ = bar
i_4h = 1
history.append(bar_)
if i_4h == 240 :
bar_ = bar
i_4h = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_4h = i_4h + 1
history[-1] = bar_
widget.clear_all()
widget.update_history(history)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("四小时")
widget.setGeometry(860, 560, 1050, 530)
widget.show()
app.exec_()
def MINUTE(q): #一分钟的是最简单的,直接使用就好。
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
def update_bar():
if not q.empty():
bar = q.get(True)
widget.update_bar(bar)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("一分钟")
widget.setGeometry(860, 15, 1050, 550)
widget.show()
app.exec_()
if __name__ == '__main__':
manager = multiprocessing.Manager()
q_1m = manager.Queue()
q_5m = manager.Queue()
q_30m = manager.Queue()
q_4h = manager.Queue()
su = manager.Queue()
pw = multiprocessing.Process(target=putbardata, args=(q_1m,q_5m,q_30m,q_4h,su))
pr_1m = multiprocessing.Process(target=MINUTE, args=(q_1m,))
pr_5m = multiprocessing.Process(target=MINUTE_5m, args=(q_5m,))
pr_30m = multiprocessing.Process(target=MINUTE_30m, args=(q_30m,))
pr_4h = multiprocessing.Process(target=MINUTE_4h, args=(q_4h,))
pw.start()
pr_1m.start()
pr_5m.start()
pr_30m.start()
pr_4h.start()
sudu = input("请输入速度:")
su.put(sudu)
time.sleep(1000000)
print('任务完成')大概说一下原理,程序设定了5个进程,通过通道交换数据,其中一个进程发送数据,另外4个进程接受数据,接受数据的四个进程就是4个周期的窗口,把接受的一分钟数据变化成3分钟30分钟等,并用图形展示出来。
只要控制发送数据的节奏,就可以动态的把行情从新演示一遍了。
这是盘后复盘用的,可以回忆一下当天到底发生了什么。
国内期货有一个盘立方软件是可以完美复盘的,数字货币没有这个东西,tradingview有这个功能,但是每月要收费90元,而且tradingview也只能使用1分钟数据复盘。
身为程序员,当然不愿意掏钱,因为自己可以写一个。
感谢vnpy提供的ChartWidget,真的很好用。
VNPY的在linux系统上装机搞得我一度想放弃。好在傻人有傻福,稀里糊涂的今天让我装成了。在此立贴纪念,同时记录一下蛋疼的探索过程,希望能够帮助各位。
尽管有大神指出对于新手最好先从WIN上玩转,但是我个人推荐在VNPY在Linux上使用。用一个IT前辈的话说,win上山容易,但是马上到山顶了上面会写一句此路不通;Linux开始上手有点困难,但是真上道了速度会奇快。
----------------------------------------------------书归正传,开始正文------------------------------------------------------------------------------------------------------------------------------
一、下载VNPY文件
(方式一)可以从github上clone或者下载压缩文件,但是对于其龟速,且容易终端,不推荐。
(方式二)在terminal上进入想让文件下载的目录中,本人是下载到了桌面,所以
1.cd到桌面 ---> cd /home/kelin110/Desktop
2.开始从gitee上拉 ---> git clone --recursive https://gitee.com/vnpy/vnpy.git 这样子在Desktop就生成了一个vnpy的文件夹
二、开始安装
1.cd vnpy
python setup.py install (个人的精力来讲,用bash install.sh就是个深坑,一头撞墙的坑)
一切顺林的话,最后会显示Finished processing dependencies for vnpy==2.1.8
进入 example/vn_trader, 跑 run.py, 命令行: python run.py
顺利的话,界面就出来了,安装完成。
4.这个界面相对win傻瓜安装版的简陋,但是进入run.py的程序你会发现,其实功能已经写好了,根据需要取消注释即可。
三、大坑总结
1.妄图调整各库版本,迎合vnpy
首先,各库情况复杂不说,由于前期已经安装了anaconda,所以算上ubuntu自带的,一共有3个python版本,各自库的位置还不一样,比如anaconda的库的位置是在anaconda3/lib/python3.8/site-packages/,而机子的自带python在/usr/lib/python3/dist-packages/,这些库有时候相互不能调用,时间长了自己都要傻掉了;尤其是pip命令返回提示说已经安装了,但是调用pip list,查看没有相应的库。那就是多个库相互影响导致的。此时需要照道已经安装的库,
例如:sudo cp ./libta_lib. /home/kelin110/anaconda3/lib/python3.8/site-packages/
其次,配合安装缺失库的时候,尽量调用conda命令来安装。
2.尽量不要偷懒用bash install.sh命令一步安装
这里有很多前辈的帖子上也反映了bash会出现各种乱七八糟的问题,其实最好的笨办法就是自己手动安装需要支持的库。这里黏贴我已经当时缺少的库,希望对大家有帮助。
sudo cp ./libta_lib. /home/kelin110/anaconda3/lib/python3.8/site-packages/ ##说明:这是将手动下载的talib编译好后复制到python库中
pip3 install -i https://pypi.doubanio.com/simple/ ta-lib ##说明:这样子写主要doubanio网速比较给力
sudo apt-get install libxcb-xinerama0 ##解决qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found.错误
前期掉的坑实在多到自己都记不住了~先写这些吧
发布于VeighNa社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2026-02-15
在《2025年VeighNa项目计划》中,我们提到将推出更多LLM相关的分享内容和社区活动,帮助用户探索大模型在量化交易领域的应用。回顾这一年的实践,AI的能力演进速度超出预期——从大模型对话问答到Agent自主执行任务,从简单的代码辅助到完整的投研开发工作流自动化,AI在实际工作流中的渗透程度不断加深。

与此同时,我们也收到了非常一致的一线反馈:大家既希望AI真正进入投研与开发流程、带来稳定提效;也希望它在私有化、本地化与可控性上保持VeighNa一贯的标准。
因此,2026年VeighNa项目的核心主题非常明确——全面拥抱Agentic AI。我们将把工作重点放在两件事上:
用更高密度的社区活动,把经验沉淀为方法论与可复用的Best Practice
2026年,我们将从专用Agent、通用Agent、VNAG课程三条主线,系统推进VeighNa的Agentic AI能力建设。
我们已经通过Agent方向小班课,在课程与项目中验证了“专用Agent”的落地路径:围绕清晰任务边界、固定输入输出与可回放的执行链路,让Agent在量化场景中真正可用。
VeighNa Assistant 已在VeighNa社区版4.3.0中提供,当前用户反馈相当不错,2026年我们将持续扩展其能力:
同时,我们也已经确定会在 VeighNa Fusion 版(面向期货公司)中集成 CTA策略投研Agent,预计3月上线。
过去一年,我们围绕 Cursor、Claude Code、Codex、Mini-Agent 等通用Agent工具做了多次社区活动探索,并逐步梳理出一条清晰的演进路径:
Agent专用知识库 → 量化投研开发环境 → 量化投研专用Skill
2026年,我们会把上述方向串成更可落地的实践链路:数据与知识如何组织、工具如何对接、任务如何拆解、结果如何评估,减少碎片化试错成本,让大家能按路线逐步进阶。
同时,我们将持续推进VeighNa项目的Agent原生化改造,核心原则是让Agent 读得懂、调得动、跑得稳,并尽量减少对个人习惯与环境的绑定,主要包括:
VNAG是我们自主研发的一套Agent开发框架,定位类似LangChain、AgentScope,但秉持着不同的设计哲学:Your Agent, Your Data。与vn.py一脉相承,VNAG优先保证用户在本地化私有环境中的运行体验,确保数据安全与部署的自主可控。
相比前文更偏应用层的专用Agent与通用Agent实践,VNAG课程将更偏向底层原理与框架设计,适合有技术能力与学习兴趣的用户深入钻研,打造自己的专属Agent。
除了技术迭代,我们也会通过更丰富的社区活动,围绕量化交易领域的Agentic AI应用,把“看懂”变成“做得出”,把“能跑”变成“能迭代”:
我学Python的目的很明确,就是量化交易。从一开始就有关注vn.py,但我学的是Python3,那时vn.py还处于版本1.x时期,所以只能望vn.py兴叹。
vn.py 2.0出来之后我并没有及时注意,等反应过来已经是2.0.7版。很兴奋,认真研究,并将心得写成《vn.py 2.0.7源代码深入分析》,分享在vn.py社区的经验分享板块。
出于对量化交易的爱好,出于对Python在量化交易中作用的认同,一定程度受vn.py强大功能的鼓舞,我与同事合写了《Python量化交易从入门到实战》一书,对vn.py的讨论是其中很重要的一部分内容。
后续又写了《vn.py 2.1.4源代码深入分析》和《vn.py 2.2.0源代码深入分析》两个文档,感谢各位老师的认可。
vn.py 3.0.0版发布于2022-03-23,这是我一直期待的一个版本,所以它刚一推出,我就立刻开始试用,并着手整理《vn.py 3.0.0源代码深入分析》。夜以继日,终于在前天完成。先发到了书籍的资源群中,接受了两天批评,现分享到此处。
写作本文档的一个主要目的是对vn.py的开源精神做出一点支持,希望本文档能够对大家学习使用vn.py有所帮助。
百度网盘链接:https://pan.baidu.com/s/1cl2MA9hNFhHlxfHM0gGe2A
提取码:s7u6
一、提前下载需要的安装包:
1、Miniconda3
https://docs.conda.io/en/latest/miniconda.html#
选择MacOSX installers里的最新版本,这里是Python 3.9下载。
2、pycharm
pycharm-community-2020.3.3.dmg
从官网上下载社区版https://www.jetbrains.com/pycharm/
3、vnpy安装包(解压后,复制文件夹到自己喜欢的位置)
从vnpy在gitee的官方地址下载最新的安装包,采用zip格式下载。
https://gitee.com/vnpy/vnpy
二、安装
1、安装Miniconda,这里是Miniconda3-latest-MacOSX-x86_64.pkg
2、添加国内源:
添加国内源:在当前用户下,编辑.condarc,内容如下:
channels:
3、创建虚拟环境
conda create -n py37_vnpy python=3.7
conda activate py37_vnpy
(退出:conda deactivate)
4、安装python.app
conda install -c conda-forge python.app
可能会因为网络问题不成功,多试几次。
5、安装pycharm-community-2020.3.3.dmg
从官网上下载社区版https://www.jetbrains.com/pycharm/
7、打开vnpy所在的文件夹,进行配置
点击‘PyCharm’菜单->Preferences菜单->Project:vnpy一级菜单->Python Interpreter二级菜单->点击右上齿轮->Add菜单->Conda Environment->Existing enviroment->Interpreter:/opy/miniconda3/envs/py37_vnpy/bin/pythonw(选择前面新建的虚拟环境的pythonw)->点OK->点OK->点OK
8、(确认在PyCharm里已经打开了vnpy项目),在PyCharm的底部,找到Terminal的标签,点击,进入py37_vnpy环境的终端,并且当前路径位于vnpy项目的文件夹。
执行以下的安装语句(requirements.txt是vnpy项目文件夹下面的一个文件),这个安装时间比较长,需要较好的网络。
pip install -r requirements.txt -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
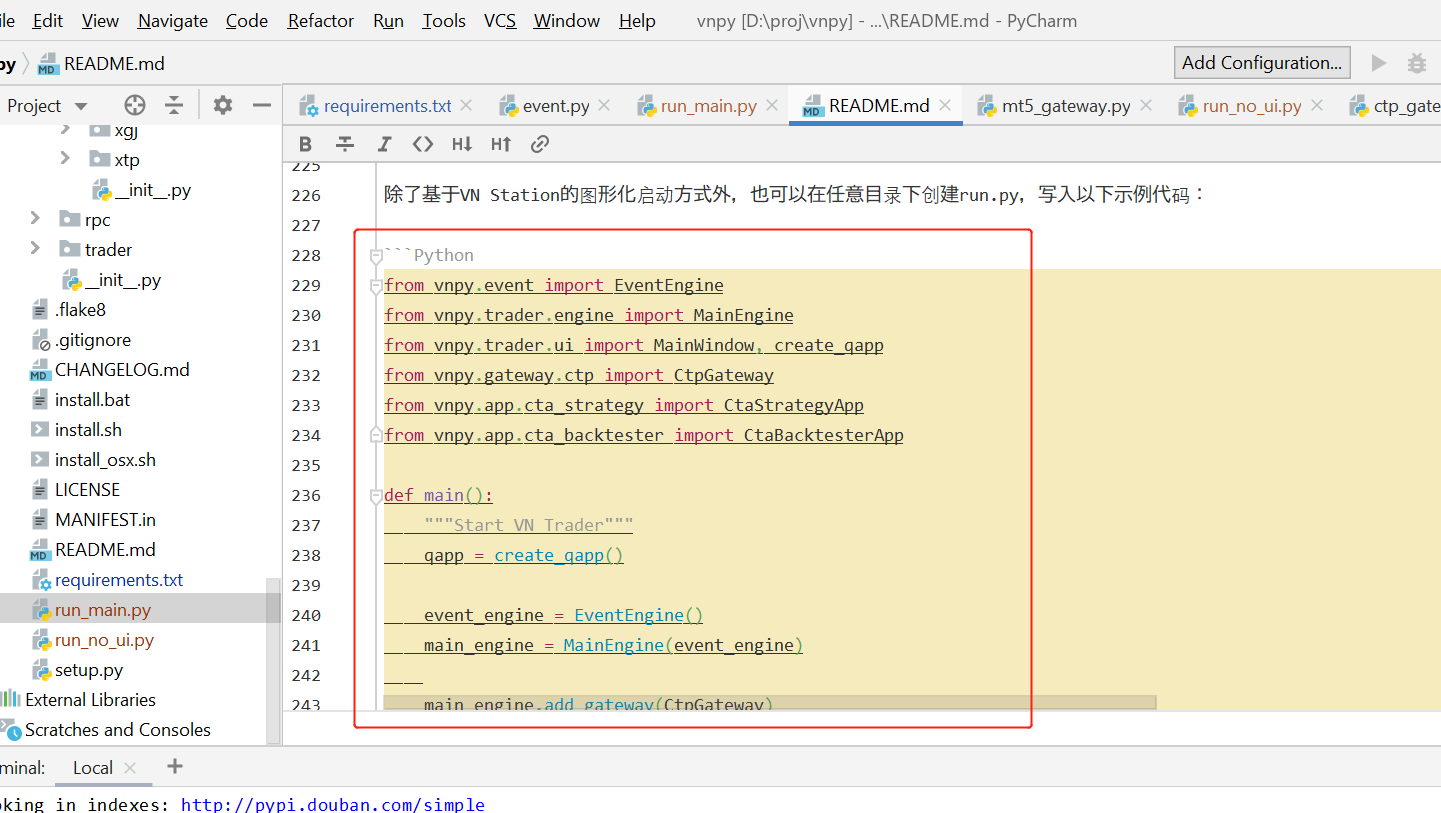
9、创建run.py文件,复制以下代码,来源 README.md
from vnpy.event import EventEngine
from vnpy.trader.engine import MainEngine
from vnpy.trader.ui import MainWindow, create_qapp
from vnpy.app.cta_strategy import CtaStrategyApp
from vnpy.app.cta_backtester import CtaBacktesterApp
def main():
"""Start VN Trader"""
qapp = create_qapp()
event_engine = EventEngine()
main_engine = MainEngine(event_engine)
# main_engine.add_gateway(CtpGateway)
main_engine.add_app(CtaStrategyApp)
main_engine.add_app(CtaBacktesterApp)
main_window = MainWindow(main_engine, event_engine)
main_window.showMaximized()
qapp.exec()
if name == "main":
main()
10、运行 python run.py,注意环境名称是 py37_vnpy

