

发布于VeighNa社区公众号【vnpy-community】
原文作者:VeighNa小助手 | 发布时间:2025-07-23
特别说明:本文内容基于我们团队在特定时间点的研究和信息收集。由于技术迭代迅速,部分信息可能存在时效性或未能完全覆盖所有细节。我们非常欢迎并期待来自社区的反馈和讨论,共同完善认知。
概述
AI 正在重塑软件开发的各个环节。当我们讨论 AI 编程时,已不再仅仅局限于代码补全。如今,我们选取了三款具有代表性的工具:Cursor、Gemini CLI 与 Claude Code,它们各自代表了不同的产品理念与技术路径。本文将对它们进行深入的对比分析,以帮助开发者理解其核心差异和独特优势。
产品定位与架构对比
Cursor
产品特点:
- 核心定位:AI 原生代码编辑器;
- 主要优势:基于 VS Code 深度整合 AI 能力,提供无缝的嵌入式体验;
- 工作模式:可视化编程环境;
- 生态支持:继承 VS Code 完整的 IDE 功能和插件生态,并提供稳定的商业化支持。
Gemini CLI
产品特点:
- 核心定位:命令行 AI 工作流工具;
- 主要优势:支持超大上下文窗口(1M+ tokens)、强大的多模态能力,且 Google Gemini 费用相对低廉;
- 工作模式:命令行交互环境;
- 生态支持:完全开源,通过 MCP 协议扩展工具生态,支持项目级与用户级配置;
Claude Code
产品特点:
- 核心定位:深度集成 IDE 的编程工作流助手;
- 主要优势:强大的代码理解能力,以及丰富的内置工具;
- 工作模式:命令行交互环境;
生态支持:支持与 VS Code、JetBrains 等多种 IDE 深度集成,提供多层级配置体系。
功能特性详细对比
IDE 集成能力
| 功能 | Cursor | Gemini CLI | Claude Code |
|---|---|---|---|
| 选区上下文共享 | 原生支持 | 通过选定文件 | 通过插件支持 |
| 标签页同步 | 完全集成 | 通过选定文件 | 通过插件支持 |
| 诊断信息共享 | 编辑器内置 | 纯命令行模式 | 通过插件支持 |
| 快捷键支持 | 多种操作快捷键 | 暂不支持 | 仅有启动快捷键 |
| 支持的 IDE | Cursor (VS Code) | 基础编辑器支持 | VS Code、JetBrains 系列 |
配置和记忆系统
| 功能 | Cursor | Gemini CLI | Claude Code |
|---|---|---|---|
| 项目级AI规则 | .cursorrules 或 .cursor/rules/ |
项目级GEMINI.md |
项目级CLAUDE.md |
| 用户级AI规则 | User Rules | 全局~/.gemini/GEMINI.md + save_memory命令 |
全局~/.claude/CLAUDE.md + #快速添加 |
| 规则执行效果 | 不够稳定 | 较为可靠 | 较为可靠 |
| 历史对话记录 | @past chats 当前对话中一键引用历史对话 | /chat save/resume 可恢复之前手动保存的对话 |
--resume 开启对话前可选择恢复自动保存的对话 |
代码生成对比
开发任务
理论对比完成后,还是要看看这三款工具在实际工作中的表现。接下来,我们将通过一个简单的 VeighNa 数据导出脚本开发任务,来对比三款工具在同一个编程任务中的生成结果与工作流程。
以下是统一使用的提示词:
作为一名精通VeighNa框架的Python开发专家,请提供一个可以直接运行的Python脚本。
核心任务:
通过调用 'get_database' 函数来创建数据库实例,进而批量导出所有K线数据。
具体要求:
1. 参考实现:
a. 'get_database' 的用法,请参考文件 'E:\github\vnpy\vnpy\trader\database.py'。
b. 数据查询和文件生成的逻辑,请参考当前 'vnpy_datamanager' 插件内的实现。
2. 本地优先:为避免使用网上过时或不兼容的代码,请完全基于本地已有的代码和您对VeighNa框架的理解来完成任务。
3. 运行时输出:脚本执行时,每处理一个数据集,都需要在控制台清晰地打印出其合约代码、时间频率和数据长度。
4. 代码质量:
a. 确保代码风格清晰、可读性好。
b. 优先使用条件判断(如 'if')处理可预见的流程,避免不必要的 'try-except' 语句。
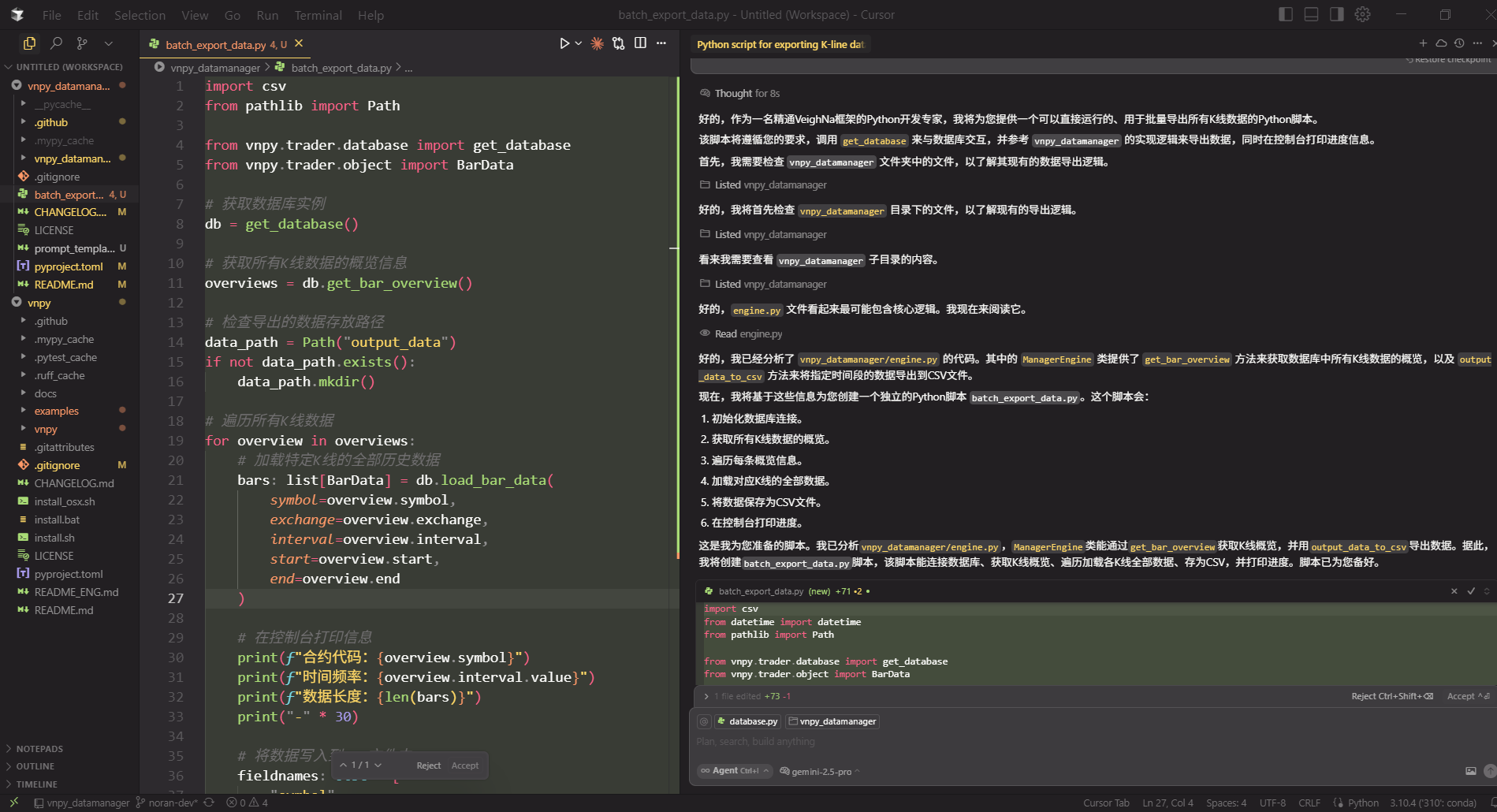
Cursor
import csv
from pathlib import Path
from vnpy.trader.database import get_database
from vnpy.trader.object import BarData
# 获取数据库实例
db = get_database()
# 获取所有K线数据的概览信息
overviews = db.get_bar_overview()
# 检查导出的数据存放路径
data_path = Path("output_data")
if not data_path.exists():
data_path.mkdir()
# 遍历所有K线数据
for overview in overviews:
# 加载特定K线的全部历史数据
bars: list[BarData] = db.load_bar_data(
symbol=overview.symbol,
exchange=overview.exchange,
interval=overview.interval,
start=overview.start,
end=overview.end
)
# 在控制台打印信息
print(f"合约代码:{overview.symbol}")
print(f"时间频率:{overview.interval.value}")
print(f"数据长度:{len(bars)}")
print("-" * 30)
# 将数据写入到CSV文件中
fieldnames: list = [
"symbol",
"exchange",
"datetime",
"open",
"high",
"low",
"close",
"volume",
"turnover",
"open_interest"
]
filename = (
f"{overview.symbol}_"
f"{overview.exchange.value}_"
f"{overview.interval.value}.csv"
)
file_path: Path = data_path.joinpath(filename)
with open(file_path, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for bar in bars:
d: dict = {
"symbol": bar.symbol,
"exchange": bar.exchange.value,
"datetime": bar.datetime.strftime("%Y-%m-%d %H:%M:%S"),
"open": bar.open_price,
"high": bar.high_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover,
"open_interest": bar.open_interest,
}
writer.writerow(d)从上图可以看出,Cursor 作为一款 AI 原生 IDE,其优势体现在与编码过程的深度融合上:
- 无缝的 IDE 集成:用户在熟悉的类 VS Code 环境中操作,通过图形界面选择模型、管理上下文、查看 Diff,学习成本低。
- 多维度的上下文管理:支持通过界面直接添加文件、利用
@符号引用代码片段或历史对话,上下文控制灵活直观。 - 强大的编码辅助:除了生成代码,它还提供实时的代码补全、智能提示,并在编码过程中利用 IDE 的 Linter 进行检查和修正。
- 支持多文件夹工作空间:可以轻松应对需要跨多个项目或代码库参考的复杂任务。
#### Gemini CLI
# export_all_data.py
import os
import csv
from datetime import datetime
from typing import List
from vnpy.trader.database import get_database, BarOverview
from vnpy.trader.object import BarData
from vnpy.trader.constant import Exchange, Interval
# 创建用于存放导出数据的文件夹
output_folder = "kline_data_exported"
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取数据库实例
# 该函数会自动读取全局配置(通常是 settings.json)来连接数据库
database = get_database()
# 获取所有K线数据的概要信息
overviews: List[BarOverview] = database.get_bar_overview()
print(f"发现 {len(overviews)} 个K线数据集,开始处理...")
print("-" * 60)
# 遍历所有数据集
for overview in overviews:
symbol: str = overview.symbol
exchange: Exchange = overview.exchange
interval: Interval = overview.interval
start: datetime = overview.start
end: datetime = overview.end
# 从数据库加载该合约的全部K线数据
bars: List[BarData] = database.load_bar_data(
symbol=symbol,
exchange=exchange,
interval=interval,
start=start,
end=end
)
data_length = len(bars)
# 检查是否有数据
if not data_length:
print(f"合约: {symbol}, 频率: {interval.value} -> 数据长度为 0, 跳过")
continue
# 打印处理信息
print(f"合约: {symbol}, 频率: {interval.value} -> 正在导出 {data_length} 条数据...")
# 构建CSV文件名和路径
file_name = f"{symbol}_{exchange.value}_{interval.value}.csv"
file_path = os.path.join(output_folder, file_name)
# 定义CSV表头
fieldnames: list = [
"symbol",
"exchange",
"datetime",
"interval",
"open",
"high",
"low",
"close",
"volume",
"turnover",
"open_interest"
]
# 将数据写入CSV文件
with open(file_path, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for bar in bars:
row_data = {
"symbol": bar.symbol,
"exchange": bar.exchange.value,
"datetime": bar.datetime.strftime("%Y-%m-%d %H:%M:%S"),
"interval": bar.interval.value,
"open": bar.open_price,
"high": bar.high_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover,
"open_interest": bar.open_interest,
}
writer.writerow(row_data)
print("-" * 60)
print(f"所有数据导出完成,文件已保存至 '{output_folder}' 文件夹。")从上图可以看出,Gemini CLI 体现了其作为命令行工具的独特工作流:
- 计划先行:在执行前,它会先分析问题、阅读代码,然后输出详细的计划步骤并提出运行建议。
- 项目为基:与 Cursor 不同,它和 Claude Code 都以项目文件夹为基础进行交互,因此对于外部文件需要指定绝对路径。
- 注重安全:Gemini CLI 非常注重安全性,在处理多文件夹交互时,推荐使用其沙盒模式来保障环境。
- 部署灵活:其纯命令行模式不仅可以在本地 IDE 中使用,也非常适合在服务器上进行远程开发。
#### Claude Code
#!/usr/bin/env python3
"""
批量导出所有K线数据的Python脚本
基于VeighNa框架的vnpy_datamanager插件实现
"""
import csv
import os
from datetime import datetime
from pathlib import Path
from vnpy.trader.database import BaseDatabase, get_database, BarOverview
from vnpy.trader.constant import Interval, Exchange
from vnpy.trader.object import BarData
def create_export_directory() -> Path:
"""创建导出目录"""
export_dir = Path("exported_kline_data")
export_dir.mkdir(exist_ok=True)
return export_dir
def generate_filename(symbol: str, exchange: Exchange, interval: Interval) -> str:
"""生成导出文件名"""
interval_name_map = {
Interval.MINUTE: "1min",
Interval.HOUR: "1hour",
Interval.DAILY: "1day"
}
interval_suffix = interval_name_map.get(interval, interval.value)
return f"{symbol}_{exchange.value}_{interval_suffix}.csv"
def export_bar_data_to_csv(
database: BaseDatabase,
file_path: str,
symbol: str,
exchange: Exchange,
interval: Interval,
start: datetime,
end: datetime
) -> bool:
"""导出K线数据到CSV文件"""
bars = database.load_bar_data(symbol, exchange, interval, start, end)
if not bars:
print(f" 警告: {symbol}.{exchange.value} {interval.value} 无数据")
return False
fieldnames = [
"symbol",
"exchange",
"datetime",
"open",
"high",
"low",
"close",
"volume",
"turnover",
"open_interest"
]
with open(file_path, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
for bar in bars:
data_row = {
"symbol": bar.symbol,
"exchange": bar.exchange.value,
"datetime": bar.datetime.strftime("%Y-%m-%d %H:%M:%S"),
"open": bar.open_price,
"high": bar.high_price,
"low": bar.low_price,
"close": bar.close_price,
"volume": bar.volume,
"turnover": bar.turnover,
"open_interest": bar.open_interest,
}
writer.writerow(data_row)
return True
def main():
"""主函数:批量导出所有K线数据"""
print("=== VeighNa K线数据批量导出工具 ===")
print("正在初始化数据库连接...")
# 获取数据库实例
database: BaseDatabase = get_database()
# 创建导出目录
export_dir = create_export_directory()
print(f"导出目录: {export_dir.absolute()}")
# 获取所有K线数据概览
print("正在获取数据库中的K线数据概览...")
overviews: list[BarOverview] = database.get_bar_overview()
if not overviews:
print("数据库中没有找到任何K线数据")
return
print(f"发现 {len(overviews)} 个数据集")
print("-" * 80)
success_count = 0
failed_count = 0
# 遍历所有数据集进行导出
for i, overview in enumerate(overviews, 1):
# 生成文件名和完整路径
filename = generate_filename(overview.symbol, overview.exchange, overview.interval)
file_path = export_dir / filename
# 输出处理信息
print(f"[{i:3d}/{len(overviews)}] 正在处理: {overview.symbol}.{overview.exchange.value} | "
f"频率: {overview.interval.value} | 数据量: {overview.count:,} 条")
print(f" 时间范围: {overview.start.strftime('%Y-%m-%d %H:%M:%S')} "
f"至 {overview.end.strftime('%Y-%m-%d %H:%M:%S')}")
# 导出数据
success = export_bar_data_to_csv(
database,
str(file_path),
overview.symbol,
overview.exchange,
overview.interval,
overview.start,
overview.end
)
if success:
file_size = os.path.getsize(file_path)
print(f" ✓ 导出成功: {filename} ({file_size:,} 字节)")
success_count += 1
else:
print(f" ✗ 导出失败: {filename}")
failed_count += 1
print()
# 输出汇总信息
print("=" * 80)
print("导出完成!")
print(f"成功导出: {success_count} 个文件")
print(f"导出失败: {failed_count} 个文件")
print(f"导出位置: {export_dir.absolute()}")
if success_count > 0:
print("\n导出的文件列表:")
for file_path in sorted(export_dir.glob("*.csv")):
file_size = os.path.getsize(file_path)
print(f" - {file_path.name} ({file_size:,} 字节)")
if __name__ == "__main__":
main()从输出过程可以看出,Claude Code 强调的是结构化的任务管理和丰富的工具生态:
- 结构化任务管理:在接收到复杂任务后,通过
TodoWrite工具将任务分解为清晰的步骤并实时展示进度,让用户对AI的工作状态一目了然。 - 人机协作流程:生成代码后会主动询问用户是否执行,提供了交互式的确认环节,增强了可控性(此行为可配置)。
- 深度 IDE 集成:支持通过快捷键在 VS Code、JetBrains 等主流 IDE 中启动,实现上下文共享、差异对比和诊断信息利用。
多模态辅助:支持便捷的图片输入,可以直接分析截图中的UI或错误信息,拓宽了交互的维度。
总结与选型建议
经过前面的详细对比和实战测试,我们对这三款工具有了全面的认识。它们各有千秋,而选择的关键在于开发者的具体需求和工作流偏好。
核心优势一览
| 工具 | 核心优势 |
|---|---|
| Cursor | AI与IDE的无缝融合体验,强大的实时编码辅助。 |
| Gemini CLI | 卓越的长上下文处理能力,高度可定制的开源框架。 |
| Claude Code | 完善的工具链生态与结构化任务管理,深度集成主流IDE。 |
适用场景推荐
Cursor:
- 提供实时的代码补全和预测(增强版智能提示)
- 无缝集成 VS Code(完整插件生态支持 + 可视化的变更检查和编辑)
- 支持多文件夹工作空间(便于在多个项目间切换开发)
- 适合需要参考历史对话的项目(@past chats 功能)
Gemini CLI:
- 适合大型代码库的分析和重构(超大上下文窗口优势)
- 适用于服务器环境和远程开发(纯命令行)
- 注重项目安全的开发环境(沙盒模式 + 请求确认机制)
- 适合需要深度定制的开发工作流(开源便于个性化开发)
Claude Code:
- 深度集成 IDE 的开发工作流(VS Code、JetBrains 自动上下文共享)
- 提供丰富的工具链(智能文件导航、智能上下文选择等)
- 支持图片辅助开发(直接传图片)
- 提供结构化项目管理(TodoWrite 任务分解和进度跟踪)
成本对比
| 工具 | 成本水平 | 免费额度 |
|---|---|---|
| Cursor | 中等 | 提供两周免费试用 |
| Gemini CLI | 低 | 包含免费层级的 API 调用,新用户可叠加 GCP 试用赠金 |
| Claude Code | 高 | 无免费版,需订阅 Pro/Max |
结语
三款工具各有其独特优势,选择应基于具体需求。随着工具的不断发展,未来的功能差距可能会缩小。每款工具都有其独特优势和适用场景,Cursor 更适合需要通过 IDE 实时编写代码的用户,Gemini CLI 适合对长上下文感知和项目安全有高要求的用户,Claude Code 则在 IDE 深度集成和丰富工具链方面表现突出。在实践中,建议开发者还是要根据自己的具体需求和工作方式选择合适的工具,或者考虑组合使用,以达到最佳的开发效率。

{kind=link}
{kind=link}
{kind=link}