
经过好几天的反复,终于完成了。所谓的复盘,就是盘后把行情从新播放一遍,如果使用tick数据,就和真实的盘面一模一样,我这里使用的是1分钟数据复盘,所以简化了很多。
代码如下:
import multiprocessing
import time
from datetime import datetime
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.database import database_manager
from vnpy.chart import ChartWidget, VolumeItem, CandleItem
from vnpy.trader.ui import create_qapp, QtCore
from vnpy.trader.object import BarData
import os
bar: BarData
def putbardata(q_1m,q_5m,q_30m,q_4h,su):
#从数据库中读取1分钟数据,你的数据库必须有下载好的数据。
bars = database_manager.load_bar_data(
symbol="APEUSDT",
exchange=Exchange.BINANCE,
interval=Interval.MINUTE,
start=datetime(2022, 5, 4),
end=datetime(2025, 1, 1)
)
sudu = 0.055
i = 0
for bar in bars:
q_1m.put(bar)
q_5m.put(bar)
q_30m.put(bar)
q_4h.put(bar)
if i > 1200: #先快速播放一定数量的一分钟bar
if not su.empty():
sudu = int(su.get(True))
print("速度已经设定为:", sudu)
if i % 10 == 1 :
os.system("pause") #正常播放以后,每10个一分钟bar暂停一下,按任意键继续,不需要这个功能的可以删掉。
time.sleep(sudu)
i = i + 1
def MINUTE_5m(q):
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history : BarData
history = []
global i_5
i_5 = 0
global bar_
def update_bar():
global i_5
global bar_
if not q.empty():
bar = q.get(True)
if i_5 == 0 :
bar_ = bar
i_5 = 1
history.append(bar_)
if i_5 == 5 :
bar_ = bar
i_5 = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_5 = i_5 + 1
history[-1] = bar_ #这一段是把一分钟数据形成5分钟数据
widget.clear_all()
widget.update_history(history) #刷新图形数据
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("五分钟") #设定五分钟窗口的标题和窗口大小以及位置
widget.setGeometry(0, 0, 900, 550)
widget.show()
app.exec_()
def MINUTE_30m(q): #30分钟和5分钟类似
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history: BarData
history = []
global i_30
i_30 = 0
global bar_
def update_bar():
global i_30
global bar_
if not q.empty():
bar = q.get(True)
if i_30 == 0 :
bar_ = bar
i_30 = 1
history.append(bar_)
if i_30 == 30 :
bar_ = bar
i_30 = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_30 = i_30 + 1
history[-1] = bar_
widget.clear_all()
widget.update_history(history)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("三十分钟")
widget.setGeometry(0, 560, 900, 550)
widget.show()
app.exec_()
def MINUTE_4h(q):
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
history: BarData
history = []
global i_4h
i_4h = 0
global bar_
def update_bar():
global i_4h
global bar_
if not q.empty():
bar = q.get(True)
if i_4h == 0 :
bar_ = bar
i_4h = 1
history.append(bar_)
if i_4h == 240 :
bar_ = bar
i_4h = 1
history.append(bar_)
else :
bar_.close_price = bar.close_price
if bar.high_price > bar_.high_price:
bar_.high_price = bar.high_price
if bar.low_price < bar_.low_price:
bar_.low_price = bar.low_price
bar_.volume = bar_.volume + bar.volume
i_4h = i_4h + 1
history[-1] = bar_
widget.clear_all()
widget.update_history(history)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("四小时")
widget.setGeometry(860, 560, 1050, 530)
widget.show()
app.exec_()
def MINUTE(q): #一分钟的是最简单的,直接使用就好。
app = create_qapp()
widget = ChartWidget()
widget.add_plot("candle", hide_x_axis=True)
widget.add_plot("volume", maximum_height=180)
widget.add_item(CandleItem, "candle", "candle")
widget.add_item(VolumeItem, "volume", "volume")
widget.add_cursor()
def update_bar():
if not q.empty():
bar = q.get(True)
widget.update_bar(bar)
timer = QtCore.QTimer()
timer.timeout.connect(update_bar)
timer.start(50)
widget.setWindowTitle("一分钟")
widget.setGeometry(860, 15, 1050, 550)
widget.show()
app.exec_()
if __name__ == '__main__':
manager = multiprocessing.Manager()
q_1m = manager.Queue()
q_5m = manager.Queue()
q_30m = manager.Queue()
q_4h = manager.Queue()
su = manager.Queue()
pw = multiprocessing.Process(target=putbardata, args=(q_1m,q_5m,q_30m,q_4h,su))
pr_1m = multiprocessing.Process(target=MINUTE, args=(q_1m,))
pr_5m = multiprocessing.Process(target=MINUTE_5m, args=(q_5m,))
pr_30m = multiprocessing.Process(target=MINUTE_30m, args=(q_30m,))
pr_4h = multiprocessing.Process(target=MINUTE_4h, args=(q_4h,))
pw.start()
pr_1m.start()
pr_5m.start()
pr_30m.start()
pr_4h.start()
sudu = input("请输入速度:")
su.put(sudu)
time.sleep(1000000)
print('任务完成')大概说一下原理,程序设定了5个进程,通过通道交换数据,其中一个进程发送数据,另外4个进程接受数据,接受数据的四个进程就是4个周期的窗口,把接受的一分钟数据变化成3分钟30分钟等,并用图形展示出来。
只要控制发送数据的节奏,就可以动态的把行情从新演示一遍了。
这是盘后复盘用的,可以回忆一下当天到底发生了什么。
国内期货有一个盘立方软件是可以完美复盘的,数字货币没有这个东西,tradingview有这个功能,但是每月要收费90元,而且tradingview也只能使用1分钟数据复盘。
身为程序员,当然不愿意掏钱,因为自己可以写一个。
感谢vnpy提供的ChartWidget,真的很好用。
发布于VeighNa社区公众号【vnpy-community】
原文作者:VeighNa小助手 | 发布时间:2026-06-15
【社区活动尊享卡】的受欢迎程度大幅超出我们的预期,为了保证每场社区活动的交流质量,尊享卡已经变更为仅对部分专业交易员用户定向提供。对于参加活动较多的同学强烈推荐!购买请扫描二维码添加小助手咨询:

过去一年里,VeighNa社区办过多场AI智能体相关的活动。已经有一些同学把这些工具用到了自己的量化投研工作里,比如辅助写策略、整理资料、跑一些重复性的流程,确实省下了不少时间。
不过也有很多同学反馈,自己虽然已经开始尝试大模型和Agent,但真正用起来还是不太顺。有时候是工具没选对,有时候是不清楚大模型到底是怎么和外部工具配合工作的,也有时候是不知道该从哪里开始,把它接到自己的量化流程里。
所以我们准备做一个【量化AI智能体学习】系列社区活动,尽量从基础讲起,一步一步带大家把这些东西真正用起来。
这个系列会尽量坚持几个原则:
目前计划先做5场:
第一场活动将于6月27日(周六)下午2:00至5:00在上海举办。普通报名仅支持线下参会,尊享卡报名可通过线上直播参与。活动具体地址将在微信群中公布,请在报名成功后扫码加入社区活动群,以便获取相关信息!
时间:6月27日 14:00-17:00
地点:上海(具体地址后续在微信群中通知)
报名费:99元(Elite会员免费参加)
报名方式:扫描下方二维码报名(报名后请扫码加入社区活动微信群获取参会地址)

最近在我工作小组内部做了一次关于风险和投资组合的基础知识分享, 主要使用了Jupyter Notebook。
把PPT和 Jupyter Notebook都传到我的Github 分享,有兴趣可以看看
https://github.com/BillyZhangGuoping/MarketDataAnaylzerbyDataFrame/tree/master/Risk%20and%20Portfolio%20Knowledge%20Sharing
主要内容标题:
这些内容在Jupyter Notebook里面都有反应。
经过一段时间学习和实践,感觉对于期货择时交易,跟随趋势基本上可以被认为是不二途径。那么对于CTA交易策略来说,及早发现趋势是非常重要。寻找趋势的方法很多,经典的比如均线快慢线交叉,布林带还有其他各种时序动量指标,这里推荐看看公众号刀疤连的一边大作‘和趋势做纯纯的朋友’,有非常全面分析。
在实践中,发现经常陷入一个两难局面,一方面是希望及时发现趋势,这样不可避免就是的判定阈值变得敏感;往往就是敏感的指标被市场白噪声和某些蓄意大宝剑图形(针对趋势交易者的迅速拉升然后砸下来图形)触发,被来回打脸,连续亏损。另一个方面为了避免被来回打脸,调高触发指标,又会导致错失趋势。
之前一直尝试用流水线质检的方法去寻找趋势策略, 和分析时序序列有点相似。质检时候,要及时发现产出是否有生产线问题,如果晚了,大量残次品出来;如果太敏感,把个体随机问题认为是生产问题,又会因为生产线停机检修造成损失。之前用的CUSUM就是这个方法。
最近有一个思路,尝试用T 检验这个方法去发现趋势。关于T 检验现在也广泛用在质量检测,药效测试。这里面还有个典故,T检验是戈斯特为了观测酿酒质量而发明的。戈斯特在位于都柏林的健力士酿酒厂担任统计学家。戈斯特于1908年在Biometrika上公布T检验,但因其老板认为其为商业机密而被迫使用笔名(学生),所以有时候也叫学生检验。
这里不准备讲解具体检验数学逻辑,具体可以搜索之,这里只是说说应用;因为也是边学边用,有错漏这出。
T检验有三种主要类型:
1.独立样本t检验:比较两组独立样本平均值的方法,这里要求两组样本 方差相等,即具有方差齐性。
2.配对样本t检验:比较同一组中不同时间(例如,相隔一年)平均值的方法。
3.单一样本t检验:检验单个组的平均值对照一个已知的平均值。
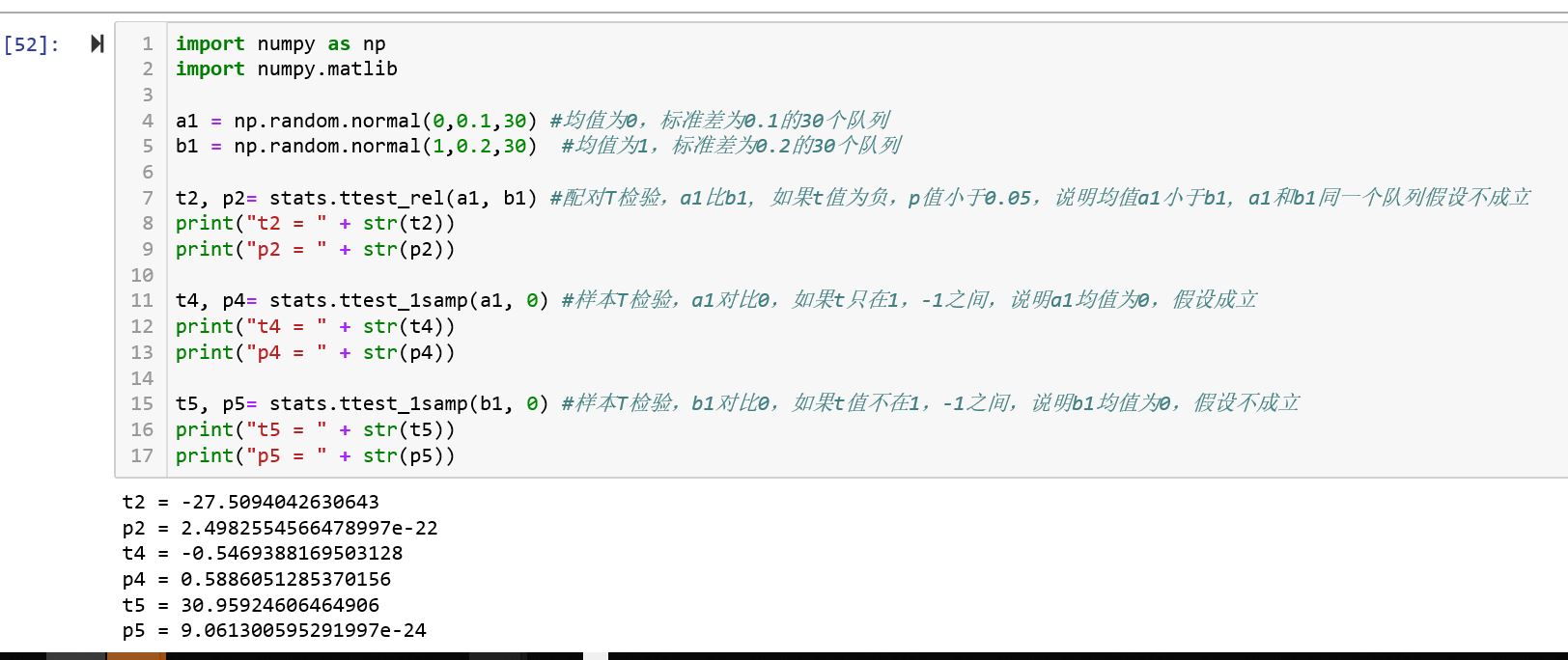
python的库stats已经提供T检验,就是stats.ttest_ind/ stats.ttest_rel/ stats.test_1samp 方法, 示例代码如下:
import numpy as np
import numpy.matlib
a1 = np.random.normal(0,0.1,30) #均值为0,标准差为0.1的30个队列
b1 = np.random.normal(1,0.2,30) #均值为1,标准差为0.2的30个队列
t2, p2= stats.ttest_rel(a1, b1) #配对T检验,a1比b1,如果t值为负,p值小于0.05,说明均值a1小于b1,a1和b1同一个队列假设不成立
print("t2 = " + str(t2))
print("p2 = " + str(p2))
t4, p4= stats.ttest_1samp(a1, 0) #样本T检验,a1对比0,如果t只在1,-1之间,说明a1均值为0,假设成立
print("t4 = " + str(t4))
print("p4 = " + str(p4))
t5, p5= stats.ttest_1samp(b1, 0) #样本T检验,b1对比0,如果t值不在1,-1之间,说明b1均值为0,假设不成立
print("t5 = " + str(t5))
print("p5 = " + str(p5))这里生成两个正态分布队列,方法很简单,返回T值,和P值;T值越接近0,则可认为假设可成立,如果T值离0值越远,比如[1,-1]之外,则假设不成立,正均值想上,小于0均值向下。
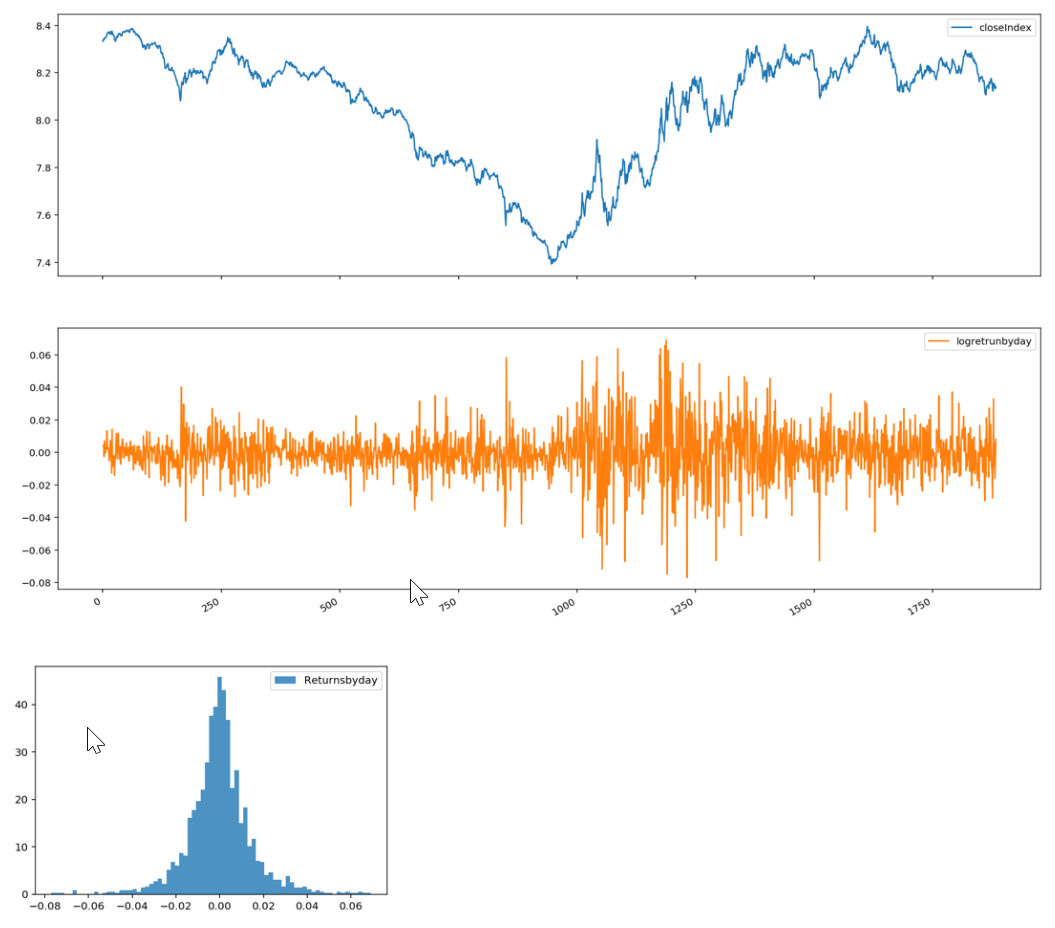
这里还有个前提,就是样本是来自正态分布总体的随机样本。而我们日常所用的期货价格分布并不是正态分布,就像CUSUM里面用的,这里使用时段(5分钟)的对数收益率,显示为近似正态分布,均值近似为0。可以考虑是否去极值,就是计算出标准差,然后将其中大于 u+3σ 的置换为u+3σ,将小于u-3σ 的置换为u-3σ,消除跳开的冲击。
下图为示意图,从close转为对数收益率,和对数收益率分布。
在CTA趋势发现时候, 这里使用主要是 配对样本t检验和单一样本t检验。
配对样本t检验:是按照时段进行对比,这里可以有相互部分覆盖的时段序列对比,比如 [t-30, t-10]和[t-20,t]对比,中间可以有10个时段相互覆盖。如果前后两个时间队列的T检验发现T值为正且大于1则,相对过往时段有趋势向上;反正向下。
单一样本t检验,用一段时间段和均值0对比,如果值在[-1.1]之间,可以认为其实没有趋势,如果大于1或者小于-1,则可以认为有向上或向下趋势。
下面简单代码示例, 是用5分钟对数收益率进行配对和样本T检测,如果连续3个配对样本的T值都大于1,或都小于-1,则去向上或向下。
dfrb5min['close']是一个close array,需要自己提前定义。
from scipy import stats
from scipy.stats import norm,t
import matplotlib.pyplot as plt
logdata = pd.DataFrame()
logdata['close'] = np.log(dfrb5min['close']) # 对数化传入5分钟close队列dfrb5min['close']
logdata['closeIndexDiff_1'] = logdata['close'].diff() # 1阶差分处理,求出对数收益率
t = 40
for i in range(t,len(logdata['close'])):
#求出配对T检测t4
t4, p4= stats.ttest_rel(logdata['closeIndexDiff_1'][i-20+1:i+1],logdata['closeIndexDiff_1'][i-30+1:i-10+1])
#求出样本T检测p0
t0, p0 = stats.ttest_1samp(logdata['closeIndexDiff_1'][i-15+1:i+1],0)
logdata.loc[i,'t'] = t4
logdata.loc[i,'t1samp'] = t0
#如果绝对值大于0,则使用
if abs(t0) > 1.0:
logdata.loc[i,'t0Index'] = t0
else:
logdata.loc[i,'t0Index'] = 0
if abs(t4) > 1.0:
logdata.loc[i,'tIndex'] = t4
else:
logdata.loc[i,'tIndex'] = 0
#csv输出
logdata.to_csv("C:\\Project\\MA8888va1min5v3.csv", index=True, header=True)
closeArray = np.array(dfrb5min['close'])
listup,listdown = [],[]
for i in range(1,len(logdata['closeO'])):
if logdata.loc[i-1,'tIndex'] >1 and logdata.loc[i,'tIndex']>1 and logdata.loc[i-1,'t0Index'] >1 and logdata.loc[i,'t0Index']>1 and logdata.loc[i-2,'tIndex']>1 and logdata.loc[i-2,'t0Index'] >1 :
listup.append(i)
elif (logdata.loc[i,'tIndex'] < -1 and logdata.loc[i-1,'tIndex'] <-1) and (logdata.loc[i,'t0Index'] < -1 and logdata.loc[i-1,'t0Index'] <-1) and logdata.loc[i-2,'tIndex']<-1 and logdata.loc[i-2,'t0Index'] <-1 :
listdown.append(i)
fig=plt.figure(figsize=(18,6))
plt.plot(closeArray, color='y', lw=2.)
plt.plot(closeArray, '^', markersize=5, color='r', label='UP signal', markevery=listup)
plt.plot(closeArray, 'v', markersize=5, color='g', label='DOWN signal', markevery=listdown)
plt.legend()
plt.show()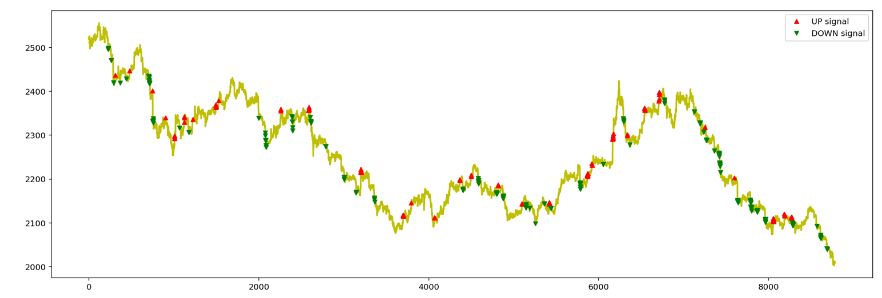
从示例图来看,有一定趋势发现能力,但是还是陷入短趋势困境,这个是时序队列长度选取,t值都有关系,还是要进一步优化。
发布于VeighNa社区公众号【vnpy-community】
原文作者: 陈晓优 | 发布时间:2024-05-18
VeighNa Elite版中针对期权量化策略交易的OptionStrategy模块发布上线已经超过半年,同时【VeighNa全实战进阶系列 - 精研期权价差策略】课程也已在两个月前更新完毕。
但可能由于期权量化策略在互联网上的公开资料相对较少,目前在VeighNa社区中依然有许多对OptionStrategy感兴趣的用户苦于不知道如何上手。
因此我们策划了《聊聊期权量化》这个系列文章,希望能够帮助大家初探期权量化策略开发、投研和实盘的整体流程,计划中的主题包括:
先来贴一下【精研期权价差策略】课程中给出的趋势动态调仓复合价差策略AdvancedSpreadStrategy,在中金所沪深300指数期权(IO)品种上的回测绩效:
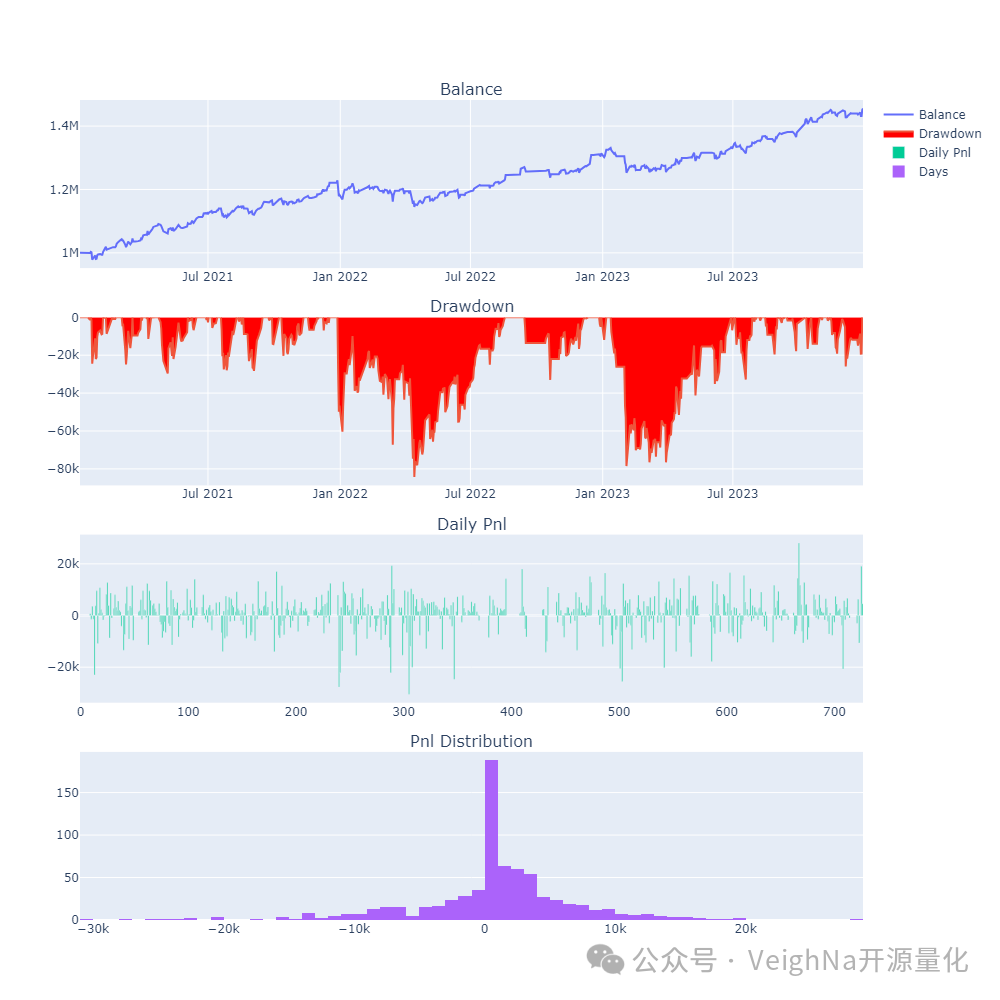
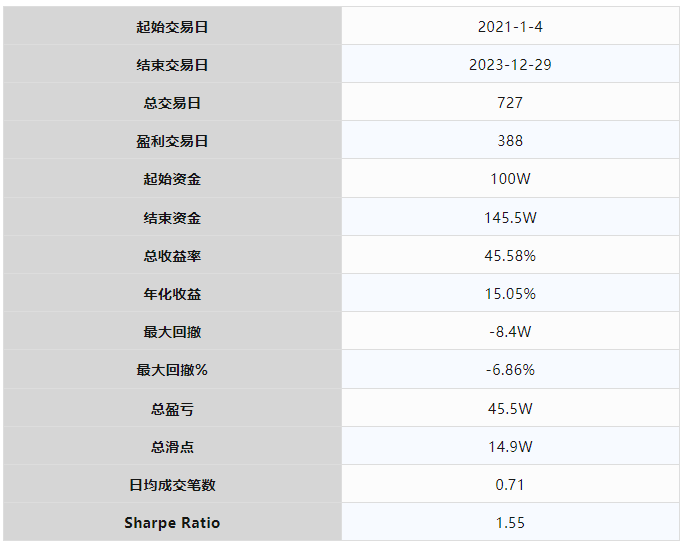
从回测图表和绩效数据中,不难看出AdvancedSpreadStrategy期权策略的一些特点:
资金曲线的整体形状更偏均值回归类策略
3年回测中策略的整体盈利表现较为稳定
策略调仓频率较低对交易成本不那么敏感
看到这里可能有些同学已经迫不及待想要上手开始,但是在那之前要给大家先泼个凉水:相较于面向期货的CTA趋势跟踪策略,期权量化策略在开发和回测中的技术难度要大的多得多。
对于绝大多数量化策略来说,无论是CTA趋势策略、价差套利策略,还是本文探讨的期权量化策略,其核心都在于解决以下四个关键问题:
而期权量化策略在解决上述四个关键问题时面临更多挑战,三个显著的难点包括:
逐日回放历史数据的回测模式
多合约历史数据截面对齐回放
策略中支持动态选择交易标的
针对上述期权策略开发中的挑战,VeighNa Elite版中引入了OptionStrategy期权量化策略模块,该模块与CtaStrategy(针对CTA策略)和PortfolioStrategy(针对组合策略)具有相似的功能,专注于期权策略的历史回测和实盘交易。OptionStrategy模块通过提供高效的策略开发、回测和优化工具,帮助用户将策略无缝应用于实盘交易中。这一过程能够显著减少交易期权时对交易员主观判断的依赖,同时提升策略执行的效率和一致性。
值得一提的是,VeighNa开源社区版中的OptionMaster模块则是专注于期权波动率交易。该模块为交易员提供了实时波动率曲面监控和期权波动率算法执行的交易功能,尽管如此,核心的交易决策仍然依赖于交易员的主观判断。
以下表格列出了两个期权模块的对比区别:

你对于期权量化策略的开发有什么疑问,或者希望在后续文章中看到的内容?欢迎在评论区留言告诉我们!!!
免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
期权没有类似simnow的服务器可以仿真调试,又不能像大佬那样直接实盘调试,
就自己做了一个工具,可以在本地播放tick数据,这样就能实现在本机仿真调试了,
现在的效果是:
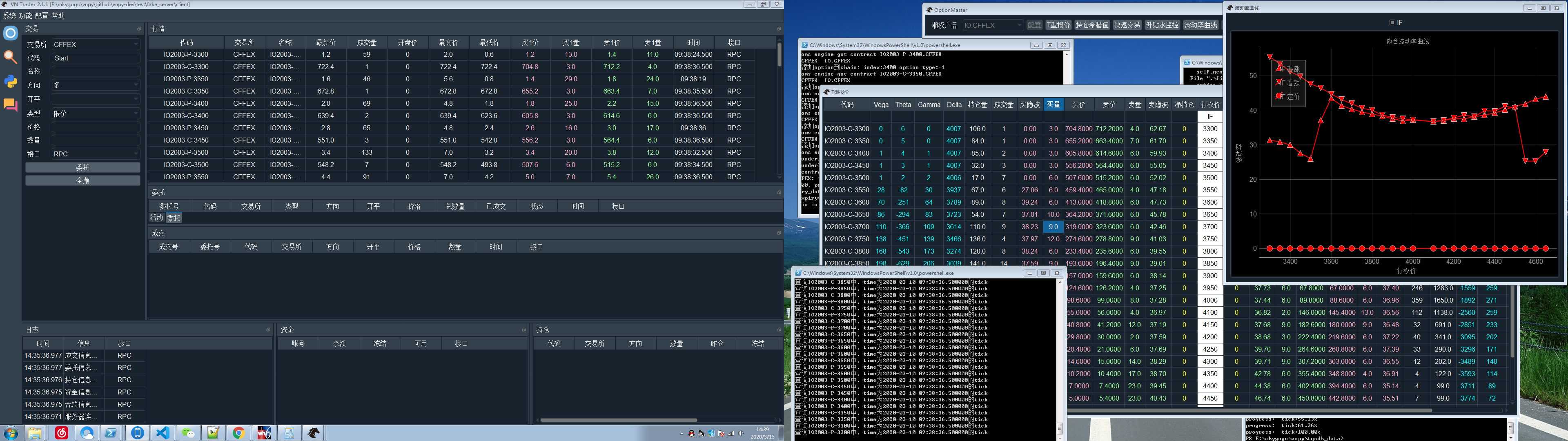
这里好像不能放附件,我放到网盘去了:
https://pan.baidu.com/s/1sgQtCgk5ivarp8OQFlKvfg
提取码:3pe6
使用方法:
1:把file_gateway放到vnpy的gateway目录下面
2:进入server目录,cmd启动server ,server目录下有我测试用的tick数据和合约配置文件,启动有可以用了
3:进入client目录,cmd启动client
4:在ui界面下链接RPC,再启动OptionMaster
5:设置期权的参数,这里注意一下,配置完,按确定后,UI上可能会有一些卡顿,因为我一次把所有tick数据都加载了,数据量比较大,我测试3月10号一天的数据,就有90M
可以留意看一下server的cmd,可以看到加载数据的详细情况
6:在主界面,“交易”选项下面,代码里输入:Start, 再敲回车, 就开始自动播放tick数据了,这时行情和T型报价应该都有对应的合约在跳动了
这个版本仅仅实现了数据流的播放,发单,撮合等等功能还在弄,有兴趣的朋友可以找我交流
大概原理:
写了一个gateway,调试的时候直接使用这个file_gateway。这里面会加载对应的tick数据,并启动一个线程以流的形式播放出来。
播放的关键是同步tick时间戳,活跃的合约可能全天的时间戳都有数据,但是不活跃的有些时间点就没有数据,需要跳过这些时间,
我实现的方法是用数据最全的合约做baseline,同步播放其他合约
我现在调试的是IO2003,对应的标的是IF2003。
标的合约一般都是最活跃的,所以用IF2003做baseline,其他合约都以他的时间戳来同步播放数据流
具体实现比较简单,有兴趣的可以看看file_gateway里面TickStreamThread的实现,数据播放快慢可以在循环里修改sleep时间
现在功能还比较简单,只能播放数据,有兴趣的朋友可以自己添加,有问题可以来群里找我:老麦
本文记录了利用python包管理生态管理工具uv,从源码恢复vnpy的运行环境的全过程。
python包管理生态中存在多种工具,如pip、pip-tools、poetry、conda等,各自具备一定功能。
uv新一代python生态管理工具,它是 Astral 公司推出的一款基于Rust编写的Python包管理工具,旨在成为“Python的 Cargo”。
它提供了快速、可靠且易用的包管理体验,在性能、兼容性和功能上都有出色表现,为 Python项目的开发和管理带来了新的选择。
与其他 Python 中的包管理工具相比,uv 更像是一个全能选手,它的优势在于:
使用uv,也可以像 Node]s 或者 Rust 项目那样方便的管理依赖。
windows上安装uv,在cmd窗口中执行下面命令:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"注意:执行完毕后,会在C:\users\\<用户名称>\.local\bin目录下安装两个文件uv.exe和uvx.exe。
进入cmd或者powershell窗口,输入uv命令应该可以得到如下回应就表示uv已经安装成功了:
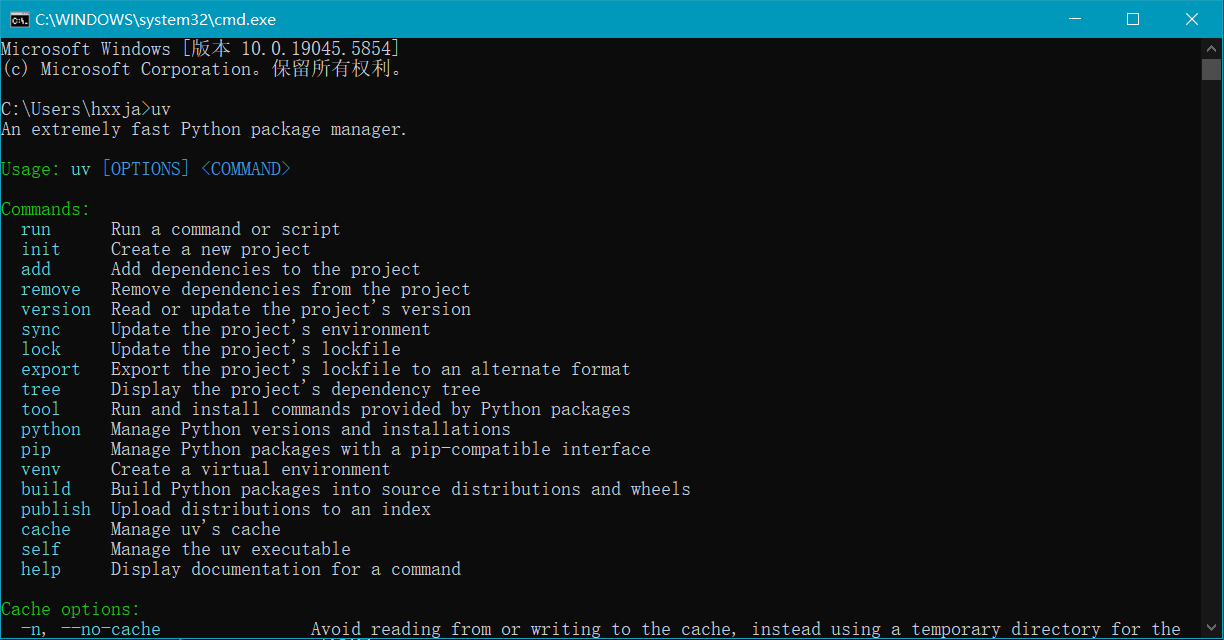
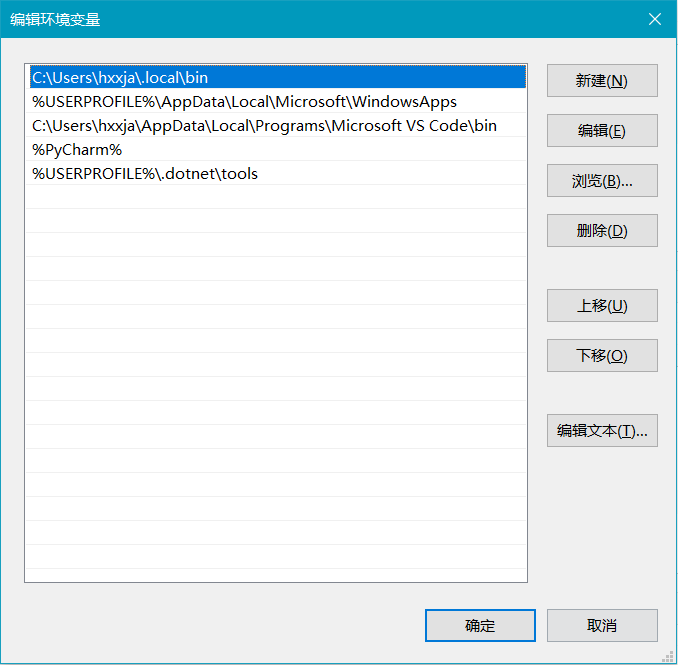
如果报告“uv不是内部或外部命令,也不是可运行的程序或批处理文件。”请打开“我的电脑”| “高级系统设置”| “环境变量”| “用户变量”| “Path”,把C:\users\\<用户名称>\.local\bin目录添加进去就可以。
三、下载vnpy 4.0源码
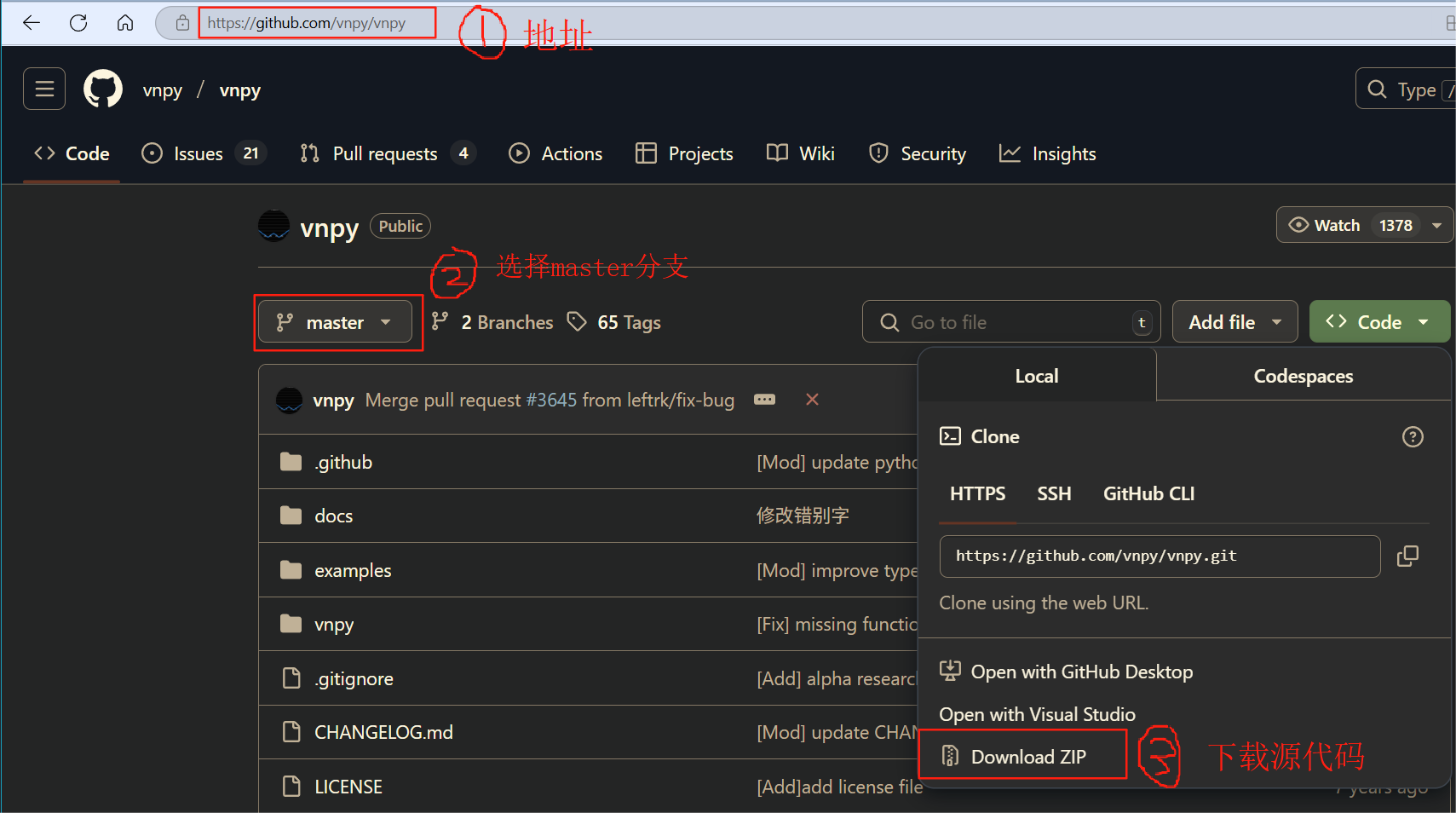
如图所示,从https://www.github.com下载到vnpy-master.zip源代码,解压后包含如下文件和目录:

输入下面的命令,限定python版本3.13,实际安装的是python 3.13.17。
uv python install 3.13来到vnpy-master源码目录下,输入下面的目录创建虚拟环境目录,当前目录下会多出.venv目录,其中包含虚拟环境的配置文件。
cd d:\vnpy-master
uv venv这一步是最关键的一步,我是好几天都无法通过这一步,最后在陈总——陈晓优的指导下才通过的。
先把ta-lib二进制包装了,注意这里必须先指明安装的源是https://pypi.vnpy.com。
uv pip install ta-lib --index=https://pypi.vnpy.comuv pip install . --index=https://pypi.vnpy.com只有vnpy核心模块是不够的,还需要根据自己的需要安装其他的模块才能够运行实际的交易:
可以合并也可以逐条执行如下命令:
uv add importlib_metadata pymysql
uv add vnpy_ctp vnpy_ctastrategy vnpy_ctabacktester vnpy_datamanager vnpy_mysql vnpy_rqdatavnpy的源码中包含一个例子,位于example\verghna_trader子目录下,其中的run.py最具代表性,它演示了如何利用已经安装的核心和其他配套模块能够完成功能:
cd d:\vnpy-master\examples\veighna_trader\
uv run run.py
作为初学者,面对 vnpy 无所不包、博大精深的丰富内容,试图用图形对 vnpy 的运行流程做一个归纳。
不到之处,还请各位多多指正

发布于VeighNa社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2026-05-31
5月中旬发布了VeighNa的4.4.0版本。本次更新的主要内容是新增QuestDB高性能时序数据库支持,同时对VeighNa Assistant的知识库和工具能力进行了进一步优化。
对于已经安装了VeighNa Studio 4.0版本的用户,可以使用快速更新功能完成自动升级。对于没有安装的用户,请下载VeighNa Studio-4.4.0,体验一键安装的量化交易Python发行版,下载链接:
https://download.vnpy.com/veighna_studio-4.4.0.exe
本次4.4.0版本中,VeighNa新增了对QuestDB时序数据库的支持,为用户在本地或者服务器上管理大规模历史行情数据提供了新的选择。
QuestDB是一款开源时序数据库,面向金融行情、物联网数据、监控指标等高频时间序列场景设计。它具备低延迟查询、高速数据读取和SQL化访问能力,适合存储Tick、K线、策略运行指标等量化交易相关数据。
对于量化投研场景来说,数据库的查询读取性能会直接影响历史数据分析、策略回测和因子计算的效率。随着用户积累的行情数据越来越多,传统数据库在大范围时间查询、聚合统计和批量读取上的压力也会逐渐增加。QuestDB针对时间序列数据进行了专门优化,可以帮助用户更高效地完成历史行情检索和投研分析工作。
QuestDB的主要特点包括:
通过接入QuestDB,VeighNa用户可以将持续增长的行情数据保存到专门的时序数据库中,并结合VeighNa已有的数据服务能力,构建更完整的本地量化研究和交易数据环境。
下面以Windows系统为例,介绍如何通过Docker快速部署QuestDB。
1. 安装Docker Desktop
首先需要在Windows上安装Docker Desktop,可以从Docker官网下载并安装:
https://www.docker.com/products/docker-desktop/
安装完成后,启动Docker Desktop,并确认Docker已正常运行。
可以在PowerShell中执行以下命令检查Docker状态:
docker version如果命令能够正常显示Docker Client和Docker Server的版本信息,说明Docker环境已经准备完成。
如果安装过程中需要配置WSL 2后端或者排查启动问题,可以参考Docker官方的Windows安装文档:
https://docs.docker.com/desktop/setup/install/windows-install/
2. 创建本地数据目录
QuestDB运行过程中会生成数据库文件。为了让数据在容器重启或删除后仍然保留,建议准备一个Windows本地目录,并将其挂载为容器内的QuestDB数据目录。
例如,可以在PowerShell中创建如下目录:
mkdir C:\questdb_data该目录将用于保存QuestDB的数据库数据。
3. 启动QuestDB容器
在PowerShell中执行以下命令启动QuestDB:
docker run -d `
--name questdb `
-p 9000:9000 `
-p 8812:8812 `
-v C:\questdb_data:/var/lib/questdb `
questdb/questdb参数说明:
--name questdb:设置容器名称为questdb。-p 9000:9000:映射QuestDB Web控制台和REST API端口。-p 8812:8812:映射PostgreSQL协议端口。-v C:\questdb_data:/var/lib/questdb:将Windows本地目录C:\questdb_data挂载到容器内的/var/lib/questdb,用于持久化保存数据库文件。questdb/questdb:使用官方QuestDB Docker镜像。启动完成后,可以通过以下命令查看容器运行状态:
docker ps4. 访问QuestDB Web控制台
容器启动成功后,在浏览器中访问:
http://localhost:9000即可打开QuestDB的Web控制台。用户可以在控制台中执行SQL查询、查看数据表,并确认数据库服务是否正常运行,如下图所示:
5. 停止和重新启动
停止QuestDB:
docker stop questdb重新启动QuestDB:
docker start questdb由于数据目录已经挂载到C:\questdb_data,容器停止或重启后,已写入的数据会继续保留。
QuestDB启动后,还需要在VeighNa的全局配置文件中启用对应的数据库配置。Windows系统下,该配置文件通常位于用户目录下的.vntrader文件夹中:
C:\Users\<用户名>\.vntrader\vt_setting.json使用编辑器打开vt_setting.json文件后,添加或修改以下字段:
{
"database.name": "questdb",
"database.host": "localhost",
"database.port": 8812,
"database.user": "admin",
"database.password": "quest",
"database.database": "qdb",
"database.http_port": 9000
}其中database.port对应QuestDB的PostgreSQL协议端口,database.http_port对应QuestDB的Web控制台和REST API端口。
需要注意的是,database.http_port是QuestDB模块使用的非标准配置字段,无法直接通过VeighNa Trader主界面的【配置】对话框修改。因此在使用QuestDB时,需要通过编辑器直接修改vt_setting.json文件。
在4.3.0版本中,我们首次在VeighNa Station中集成了VeighNa Assistant智能助手。本次4.4.0版本继续围绕实际使用体验进行优化,主要包括VNAG框架本身的功能升级,以及VeighNa知识库内容的补充完善。
VNAG功能升级
新版VNAG增加了会话历史导出功能,方便用户保存和整理Assistant的问答记录。同时,我们也优化了工具执行调度逻辑,使Assistant在处理代码理解、文件检索、问题排查等复杂任务时,能够更稳定地完成多步骤工具调用。
知识库内容升级
本次更新还补充了来自社区渠道的FAQ内容,包括交流群、论坛等场景中用户经常遇到的安装、配置、开发和排错问题。随着这些常见问题被纳入知识库,Assistant在回答VeighNa实际使用问题时可以给出更贴近社区经验的参考。
新增
调整
修复
发布于VeighNa社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2026-05-29
在上一篇里,我们已经读懂了 AlphaStrategy 的基本职责:它从信号表中读取当日预测分数,根据策略规则生成目标持仓,并通过 set_target 和 execute_trading 把调仓意图交给回测引擎。
接下来要回答的问题是:回测引擎如何把这套策略放进历史行情里逐日运行,并最终生成净值、回撤和统计指标?
这就是本篇要讨论的 事件驱动历史回测。在 vnpy.alpha 中,BacktestingEngine 负责加载历史 K 线、按时间推进回放、触发策略回调、撮合委托、更新资金持仓,并计算最终回测结果。
对于已经理解前几篇内容的读者来说,本篇重点关注:
BacktestingEngine 的典型使用顺序
事件驱动回测会沿着历史时间逐日推进。每推进到一个交易日,回测引擎取出当日 K 线,先处理已有委托,再把行情切片推送给策略,由策略根据当日信息生成新的调仓动作。
对日频截面策略来说,可以把每个交易日理解为一个事件:
on_bars(bars) 回调。这种回放方式更接近真实交易流程:策略在当前时间点做决策,委托成交取决于当时的行情,资金、持仓、手续费也会随着成交逐步变化。
可以先用下面这张图建立整体印象:
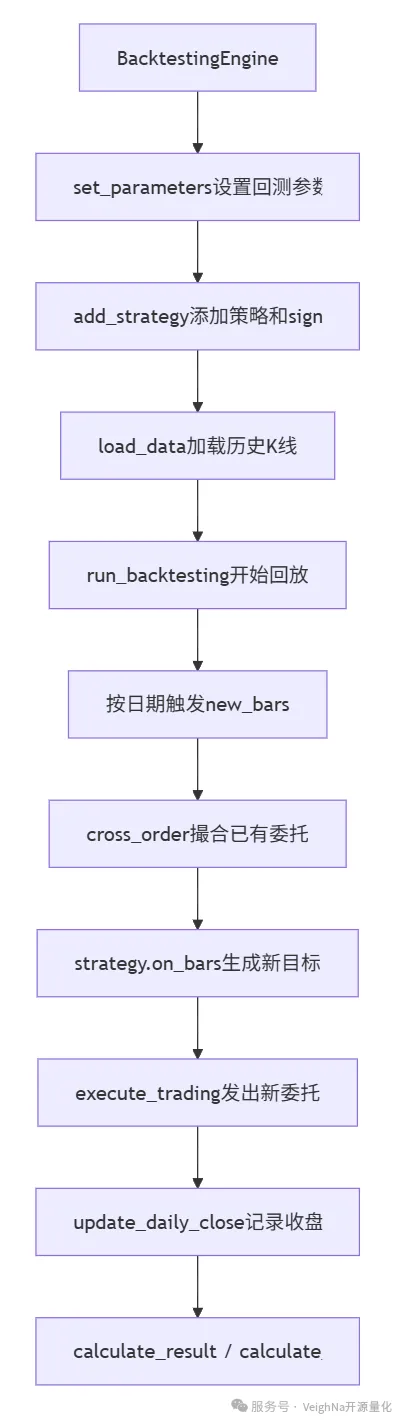
一个典型的 BacktestingEngine 使用流程如下:
from vnpy.trader.constant import Interval
from vnpy.alpha import BacktestingEngine
from vnpy.alpha.strategy.strategies.equity_demo_strategy import EquityDemoStrategy
engine = BacktestingEngine(lab)
engine.set_parameters(
vt_symbols=component_symbols,
interval=Interval.DAILY,
start=start,
end=end,
capital=1_000_000,
)
engine.add_strategy(
EquityDemoStrategy,
setting={
"top_k": 50,
"n_drop": 5,
"min_days": 3,
"cash_ratio": 0.95,
},
signal_df=signal_df,
)
engine.load_data()
engine.run_backtesting()
daily_df = engine.calculate_result()
statistics = engine.calculate_statistics()
engine.show_chart()各步骤的职责可以按顺序理解。
set_parameters 设置回测标的、K 线周期、起止日期、初始资金、无风险利率和年化交易日数量。同时,它会从 AlphaLab 的 contract.json 中读取各标的的费率、合约乘数和最小变动价位。
add_strategy 创建策略实例,并把策略参数和 signal_df 交给回测引擎。策略通过模板方法向引擎查询信号、资金和持仓,实际的行情推进和撮合过程仍由引擎统一管理。
load_data 从 AlphaLab 中读取各标的历史 K 线,并缓存到回测引擎内部。若某些标的没有历史数据,会在日志中输出提示。
run_backtesting 按日期回放历史行情。每个交易日都会触发一次 new_bars(dt),再由它推动撮合、策略回调和收盘记录。
calculate_result 根据成交和每日收盘价计算逐日盯市盈亏,生成 daily_df。
calculate_statistics 在 daily_df 基础上计算收益、回撤、手续费、成交金额、夏普比率等统计指标。
show_chart 使用图表展示资金曲线、回撤、每日盈亏和盈亏分布。
上一篇已经说明,信号表通常包含三列:
datetimevt_symbolsignal在回测中,信号表通过 add_strategy(..., signal_df=signal_df) 传入引擎。策略内部调用 self.get_signal() 时,实际会转到回测引擎的 get_signal() 方法。
这个方法会取当前回测时间 self.datetime,然后从 signal_df 中筛选出同一天的信号:
signal = self.signal_df.filter(pl.col("datetime") == dt)信号日期和行情日期需要保持对齐。如果 signal_df 中没有当前日期对应的预测值,回测日志会提示找不到该日期的信号。排查时可以先看几项:
datetime 类型或时区处理不一致这里可以先记住一个关键点:回测会在每个交易日只取当天那一小片信号。 策略看到的是当前日期对应的截面;整张信号表只是历史预测结果的存储容器,回放时会按日期切片使用。
run_backtesting 会把所有历史交易日排序,然后逐日调用 new_bars(dt)。new_bars 是理解事件驱动流程的关键。
它主要做四件事。
第一步:准备当日 K 线切片。
引擎会遍历所有 vt_symbols,从历史数据缓存中取出当前日期、当前标的的 BarData。如果某个标的当天没有新 K 线,但之前有缓存行情,引擎会用前一日收盘价构造填充 K 线,用于维持持仓盯市。
第二步:撮合已有委托。
策略上一日或之前发出的未成交委托,会先进入 cross_order() 尝试撮合。撮合时会根据当日 K 线的开高低收、委托价格、涨跌停约束等条件判断是否成交。
买入委托在价格达到可成交条件、且当日没有处于整日涨停限制时,进入成交流程;卖出委托在价格达到可成交条件、且当日没有处于整日跌停限制时,进入成交流程。
第三步:触发策略回调。
撮合完成后,引擎调用:
self.strategy.on_bars(bars)这时策略会读取当日信号、更新持仓天数、生成卖出和买入列表、调用 set_target,最后通过 execute_trading 发出新的调仓委托。
这里的关键时点是:new_bars 会先撮合已有委托,再调用 strategy.on_bars(bars)。策略在 on_bars 中生成的新委托,会等待后续行情推进时再进入撮合流程。这样可以把信号读取、委托生成和成交时点区分开。
第四步:记录每日收盘。
策略回调结束后,引擎会调用 update_daily_close,把当日各标的收盘价记录下来。后续 calculate_result 会基于这些价格、成交记录和持仓变化计算逐日盯市盈亏。
AlphaStrategy.execute_trading 会比较目标仓位和当前仓位:
diff = target - pos如果 diff > 0,说明需要买入或补回;如果 diff < 0,说明需要卖出或做空。对于当前的股票多头 Demo 策略,最常见的是买入开仓和卖出平仓。
委托价格会按 price_add 做调整:
close_price * (1 + price_add)close_price * (1 - price_add)在这里,price_add 表示回测中的委托价格调整假设:买入时适当提高委托价,卖出时适当降低委托价,用来提高撮合概率。实盘环境中的滑点、排队和成交概率,还需要结合具体交易系统另行评估。
成交发生后,回测引擎会根据 contract.json 中的配置计算资金变化:
long_rate:买入费率short_rate:卖出费率(包含印花稅)size:合约乘数pricetick:最小变动价位如果某个 vt_symbol 在 contract.json 中缺少配置,set_parameters 时会输出告警。此时手续费、乘数等计算可能不完整。回测前最好确认所有回测标的都有对应配置。
回测结束后,通常先调用:
daily_df = engine.calculate_result()
statistics = engine.calculate_statistics()calculate_result 会生成逐日结果表,其中常见字段包括:
trade_count:当日成交笔数turnover:当日成交金额commission:当日手续费trading_pnl:交易盈亏holding_pnl:持仓盈亏total_pnl:总盈亏net_pnl:扣除手续费后的净盈亏calculate_statistics 则会进一步输出和返回统计指标,例如:
图表方面,show_chart 会展示资金曲线、回撤、每日盈亏和盈亏分布。若需要和基准指数对比,还可以使用 show_performance(benchmark_symbol) 查看相对收益、超额收益和成本影响。
回测统计指标评价的是完整组合流程。它包含策略规则、成交假设、费用、持仓和资金曲线,视角已经从“预测分数”推进到了“组合表现”。
事件驱动回测多了行情、成交和资金环节,排查时可以按下面几类逐项检查。
1. 找不到合约交易配置。
如果日志提示找不到某个合约的交易配置,通常说明 contract.json 中缺少该 vt_symbol。需要回到数据准备阶段,确认对所有回测标的都调用过 add_contract_setting。
2. 部分标的历史数据为空。
load_data 会逐个标的读取历史 K 线。如果某些标的没有数据,回测仍可能继续,但实际股票池已经变小。应检查 daily/{vt_symbol}.parquet 是否存在,以及日期范围是否覆盖回测区间。
3. 找不到某日信号预测值。
这通常是 signal_df 的 datetime 与回测行情日期不一致,或者信号只覆盖了部分日期。建议检查 signal_df["datetime"].min()、signal_df["datetime"].max() 是否覆盖回测区间。
4. 有信号但没有成交。
可以按顺序检查:是否有对应行情,委托价格是否满足撮合条件,是否受到涨跌停约束,目标仓位和当前仓位是否相同,可用资金是否足够。确认策略确实调用了 set_target 后,再继续查看委托和成交记录。
5. 回测结果和信号分析差异很大。
信号分析只看预测分数和未来收益关系;回测还包含持仓数量、换手、费用、成交、现金比例等约束。若两者差异很大,应重点检查策略参数、交易成本和日期对齐。
这一篇的重点,是把 BacktestingEngine 在投研链路中的位置讲清楚:它承接前面已经准备好的信号和策略规则,把它们放入历史行情中逐日运行,完成行情推进、委托撮合、持仓更新、资金变化和统计指标计算。
可以先记住这条顺序:
信号表 + 策略规则 -> 历史行情回放 -> 委托撮合 -> 持仓资金变化 -> 逐日盈亏和统计指标
到这里,vnpy.alpha 入门系列已经串起了从 AlphaLab 数据准备、AlphaDataset 因子标签、AlphaModel 模型预测、AlphaStrategy 策略规则,到 BacktestingEngine 历史回测的完整主线。后续如果继续深入学习,可以围绕自定义因子、自定义模型、自定义策略参数优化和更严格的样本外验证展开。

