很多时候,需要用CSV文件直接回测
先看用法:
from vnpy.app.cta_strategy.csv_backtesting import CsvBacktestingEngine, OptimizationSetting
from vnpy.app.cta_strategy.base import BacktestingMode
from vnpy.app.cta_strategy.strategies.atr_rsi_strategy import (
AtrRsiStrategy,
)
from datetime import datetime
engine = CsvBacktestingEngine()
engine.set_parameters(
vt_symbol="IF88.CFFEX",
interval="1m",
start=datetime(2016, 1, 1),
end=datetime(2019, 4, 30),
rate=0.3/10000,
slippage=0.2,
size=300,
pricetick=0.2,
capital=1_000_000,
)
engine.add_strategy(AtrRsiStrategy, {})
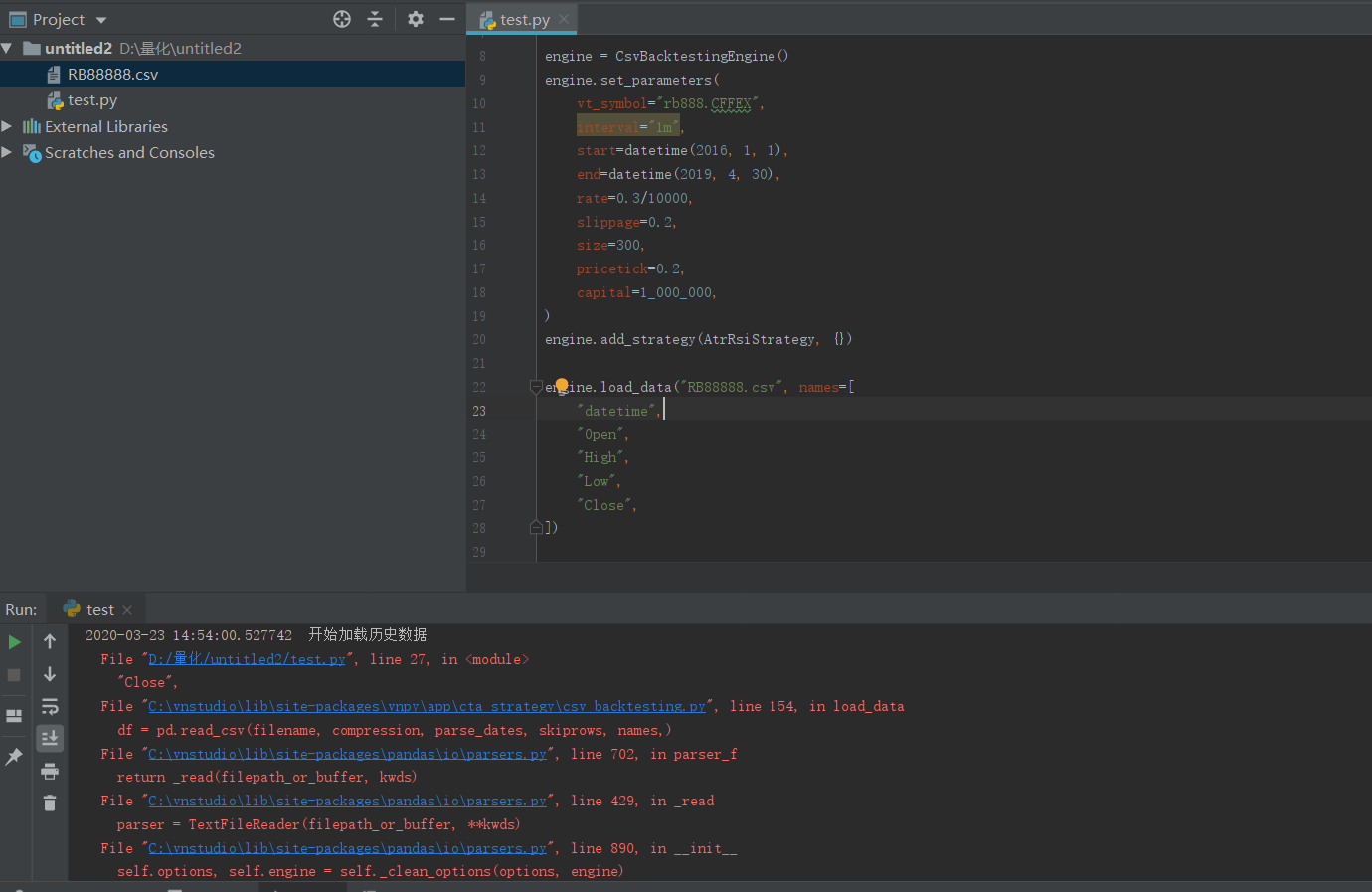
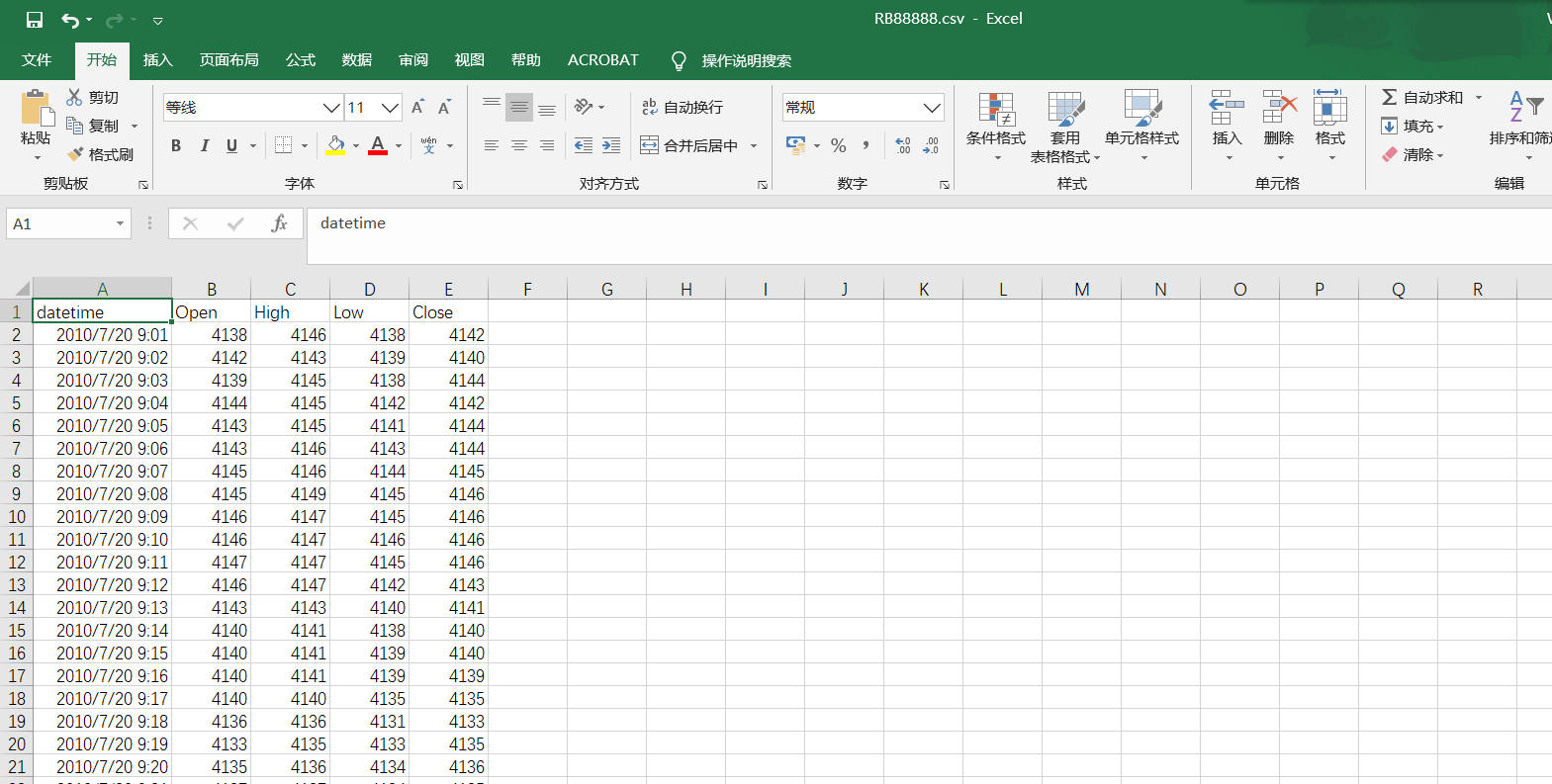
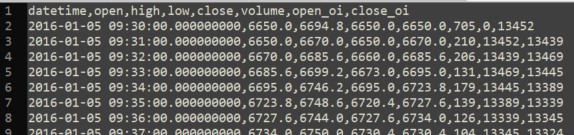
engine.load_data("data.csv", names = [
"datetime",
"open_price",
"high_price",
"low_price",
"close_price",
"volume",
"open_interest",
])
engine.run_backtesting()
df = engine.calculate_result()
engine.calculate_statistics()
engine.show_chart()
将下列代码命名为csv_backtesting.py保存到 cta_strategy 目录下并且与backtesting.py 同一目录
import pandas as pd
from vnpy.app.cta_strategy.backtesting import *
def generate_bar_from_row(row, symbol, exchange):
"""
Generate bar from row.
"""
return BarData(
symbol=symbol,
exchange=Exchange(exchange),
interval=Interval.MINUTE,
open_price=row["open"],
high_price=row["high"],
low_price=row["low"],
close_price=row["close"],
open_interest=row["open_interest"] or 0,
volume=row["volume"],
datetime=row.name.to_pydatetime(),
gateway_name="DB",
)
def generate_tick_from_row(row, symbol, exchange):
"""
Generate tick from row.
"""
return TickData(
symbol=symbol,
exchange=Exchange(exchange),
datetime=row["datetime"],
name=row["name"],
volume=row["volume"],
open_interest=row["open_interest"],
last_price=row["last_price"],
last_volume=row["last_volume"],
limit_up=row["limit_up"],
limit_down=row["limit_down"],
open_price=row["open_price"],
high_price=row["high_price"],
low_price=row["low_price"],
pre_close=row["pre_close"],
bid_price_1=row["bid_price_1"],
bid_price_2=row["bid_price_2"],
bid_price_3=row["bid_price_3"],
bid_price_4=row["bid_price_4"],
bid_price_5=row["bid_price_5"],
ask_price_1=row["ask_price_1"],
ask_price_2=row["ask_price_2"],
ask_price_3=row["ask_price_3"],
ask_price_4=row["ask_price_4"],
ask_price_5=row["ask_price_5"],
bid_volume_1=row["bid_volume_1"],
bid_volume_2=row["bid_volume_2"],
bid_volume_3=row["bid_volume_3"],
bid_volume_4=row["bid_volume_4"],
bid_volume_5=row["bid_volume_5"],
ask_volume_1=row["ask_volume_1"],
ask_volume_2=row["ask_volume_2"],
ask_volume_3=row["ask_volume_3"],
ask_volume_4=row["ask_volume_4"],
ask_volume_5=row["ask_volume_5"],
gateway_name="DB",
)
class CsvBacktestingEngine(BacktestingEngine):
def __init__(self):
super().__init__()
def load_data(
self,
filename: str,
names: list = [
"datetime",
"open_price",
"high_price",
"low_price",
"close_price",
"volume",
"open_interest",
],
compression: any = None,
parse_dates: bool = True,
skiprows: int = 1,
):
"""
Load Bar Names: [
"datetime",
"open_price",
"high_price",
"low_price",
"close_price",
"volume",
"open_interest",
]
Load Tick Names: [
"datetime",
"name",
"volume",
"open_interest",
"last_price",
"last_volume",
"limit_up",
"limit_down",
"open_price",
"high_price",
"low_price",
"pre_close",
"bid_price_1",
"bid_price_2",
"bid_price_3",
"bid_price_4",
"bid_price_5",
"ask_price_1",
"ask_price_2",
"ask_price_3",
"ask_price_4",
"ask_price_5",
"bid_volume_1",
"bid_volume_2",
"bid_volume_3",
"bid_volume_4",
"bid_volume_5",
"ask_volume_1",
"ask_volume_2",
"ask_volume_3",
"ask_volume_4",
"ask_volume_5",
]
"""
self.output("开始加载历史数据")
if not self.end:
self.end = datetime.now()
if self.start >= self.end:
self.output("起始日期必须小于结束日期")
return
self.history_data.clear() # Clear previously loaded history data
# Load 30 days of data each time and allow for progress update
progress_delta = timedelta(days=30)
total_delta = self.end - self.start
interval_delta = INTERVAL_DELTA_MAP[self.interval]
start = self.start
end = self.start + progress_delta
progress = 0
while start < self.end:
end = min(end, self.end) # Make sure end time stays within set range
df = pd.read_csv(filename, compression, parse_dates, skiprows, names,)
# Generate
symbol, exchange = self.vt_symbol.split(".")
data = []
if df is not None and not df.empty:
for ix, row in df.iterrows():
if row["datetime"] > self.start and row["datetime"] < self.end:
if self.mode == BacktestingMode.BAR:
data.append(generate_bar_from_row(row, symbol, exchange))
else:
data.append(generate_tick_from_row(row, symbol, exchange))
else:
self.output("Csv file has no Data!")
return
self.history_data.extend(data)
progress += progress_delta / total_delta
progress = min(progress, 1)
progress_bar = "#" * int(progress * 10)
self.output(f"加载进度:{progress_bar} [{progress:.0%}]")
start = end + interval_delta
end += progress_delta + interval_delta
self.output(f"历史数据加载完成,数据量:{len(self.history_data)}")