

发布于vn.py社区公众号【vnpy-community】
《30天解锁Python量化开发》课程已经更新过半(至25集),计划在9月底全部更新完毕,通过概念讲解和实践操作结合的方式,加上vn.py框架内部代码细节的梳理学习,来帮助你快速掌握Python量化开发能力,详情请戳。
原文作者:KeKe | 发布时间:2020-09-15
不管是研究价差套利策略还是多因子组合策略,都需要同时用到诸多合约的历史数据。
而vn.py目前提供的图形界面数据下载工具(CtaBacktester和DataManager两个模块),每次操作只能下载一个合约的数据,当要下载的合约数量较多时,逐个点过去既浪费时间也容易误操作。
本文中,我们将来介绍如何通过Python脚本执行的形式,直接调用vn.py框架内的数据下载和整理入库功能,来实现全市场期货数据的批量下载和自动更新。
全市场数据批量下载
设置合约品种
首先,我们要先生成一个字典,来指定需要下载的数据,关键字段有3个:
- 交易所代号:上期所-> SHFE
- 合约代号: 螺纹钢-> rb
- 合约品种类型: 指数合约 -> 99
基于以上字段,我们即可生成在使用rq_client(位于vnpy.trader.rqdata模块中)下载数据时所需的本地代码vt_symbol(如rb99.SHFE)。
然后,由于要下载全市场品种的行情数据,所以采用字典和列表嵌套的复合数结构来表示:
symbols = {
"SHFE": ["cu", "al", "zn", "pb", "ni", "sn", "au", "ag", "rb", "wr", "hc", "ss", "bu", "ru", "nr", "sp", "sc", "lu", "fu"],
"DCE": ["c", "cs", "a", "b", "m", "y", "p", "fb","bb", "jd", "rr", "l", "v", "pp", "j", "jm", "i", "eg", "eb", "pg"],
"CZCE": ["SR", "CF", "CY", "PM","WH", "RI", "LR", "AP","JR","OI", "RS", "RM", "TA", "MA", "FG", "SF", "ZC", "SM", "UR", "SA", "CL"],
"CFFEX": ["IH","IC","IF", "TF","T", "TS"]}
symbol_type = "99"在symbols字典中,每个键(key)是交易所的英文缩写,而对应的值(value)则是包含了该交易所各期货品种英文前缀的列表。这样在使用时只需要遍历这个字典,就可以快速生成所有如rb99.SHFE这样结构的本地代码。
设置下载时间段
这一步我们只需对所有品种设置相同的下载数据开始时间和结束时间即可。需要注意的是,rq_client中关于时间的参数采用datetime.datetime格式,所以这里要做到格式的一致,代码如下:
from datetime import datetime
start_date = datetime(2005,1,1)
end_date = datetime(2020,9,10)
执行批量下载任务
完成了前面的两步准备,最后就是运行脚本来执行批量下载任务,脚本的整理逻辑步骤如下:
- 遍历symbols字典
- 生成不同的HistoryRequest参数
- 调用数据下载模块rqdata_client.query_history,得到数据data
- 调用数据保存模块database_manager.save_bar_data,把下载好的数据data写入数据库
from vnpy.trader.rqdata import rqdata_client
from vnpy.trader.database import database_manager
from vnpy.trader.constant import Exchange, Interval
from vnpy.trader.object import HistoryRequest
def load_data(req):
data = rqdata_client.query_history(req)
database_manager.save_bar_data(data)
print(f"{req.symbol}历史数据下载完成")
for exchange, symbols_list in symbols.items():
for s in symbols_list:
req = HistoryRequest(
symbol=s+symbol_type,
exchange=Exchange(exchange),
start=start_date,
interval=Interval.DAILY,
end=end_date,
)
load_data(req)写好脚本文件后可以在cmd中通过python命令来直接运行,或者也可以选择将代码写在Jupyter Notebook来运行。每完成一个品种的下载任务后会打印输出相应的日志信息:

如果要下载小时或者分钟级别数据,只需把上一段代码中创建HistoryRequest对象时的interval参数,由日线周期的Interval.DAILY改成分钟线的Interval.MINUTE或者小时线的Interval.HOUR即可。
每日定时自动更新
尽管已经构建了包含全市场品种的历史数据库,但随着每日交易数据的不断产生,还是需要每天下载新的数据来更新数据库。
每日定时执行
通常我们希望在收盘后的某个时间点(比如下午5点),来自动执行数据更新任务。最简单的方案就是在Python脚本中启动一个持续运行的while循环,然后不断检测当前时间,到下午5点时就开始下载更新数据,其他时间则sleep等待,相关代码如下:
from datetime import datetime, time
from time import sleep
last_dt = datetime.now()
start_time = time(17,0)
while True:
dt = datetime.now()
if dt.time() > start_time and last_dt.time <= start_time:
download_data()
last_dt = dt
增量更新逻辑
数据库中已有的数据没必要重复下载,因此在执行每日数据更新时,应该选择当前数据库中每个合约的最新一条数据的时间作为今日更新下载的起始时间点(start_time)。这样在前一天已经批量下载完全市场所有合约的数据后,今天就只需要下载当日内产生的新数据即可。
增量更新的原理步骤如下:
1)通过database_manager(位于vnpy.trader.database模块中)来查询当前数据库中已有的合约数据统计情况:
data = database_manager.get_bar_data_statistics()2)遍历data列表中各合约数据的统计信息,查询每个合约所对应的最新一条数据的时间戳:
for d in data:
newest_bar = database_manager.get_newest_bar_data(
d["symbol"], Exchange(d["exchange"]), Interval(d["interval"])
)
d["end"] = newest_bar.datetime3)针对每个合约的数据更新,起始时间均为数据库中最新一条数据的时间戳,结束时间则是当前最新时间戳:
end_date = datetime.now()
for d in data:
symbol = d["symbol"]
exchange = d["exchange"]
req = HistoryRequest(
symbol=symbol,
exchange=Exchange(exchange),
start=d["end"],
interval=Interval.DAILY,
end=end_date,
)
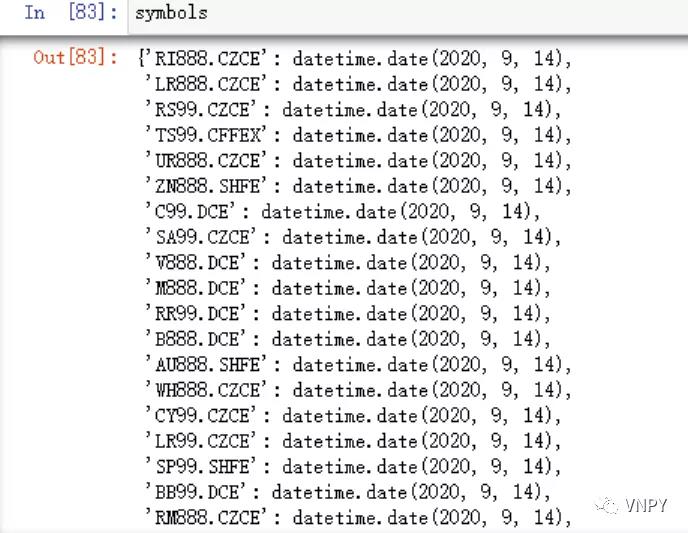
load_data(req=req)运行完成后,我们可以重复1、2两步来查询数据库中已有数据的最新一条记录时间戳,发现已经成功更新了今日所有合约的数据:
9月26日社区线下活动:CTA策略复杂交易算法实现
内容:
CTA策略复杂交易算法:
a.回调函数细节:
i. on_tick的K线合成
ii. on_order的推送时机
iii. on_trade的持仓更新
b. CTA交易中的算法状态机
c. 替换频繁cancel_all模式的停止单d. 盘口连续挂单的交易执行逻辑
e. 实现一个策略内的TWAP算法
K线图表绘制回测买卖记录
a.成交的逐笔对冲统计模式
b. vnpy.chart模块的图层开发
c. 实现买卖记录连线图层
报名请扫描下方二维码:

