

发布于vn.py社区公众号【vnpy-community】
原文作者:用Python的交易员 | 发布时间:2020-06-12
提示:如果只对封面3D图实现感兴趣的同学,可以直接跳转到文末的第三段内容~
当前的情况
对于CTA策略的回测研究,vn.py提供了两套工具:CtaBacktester图形界面
和CtaStrategy回测引擎。
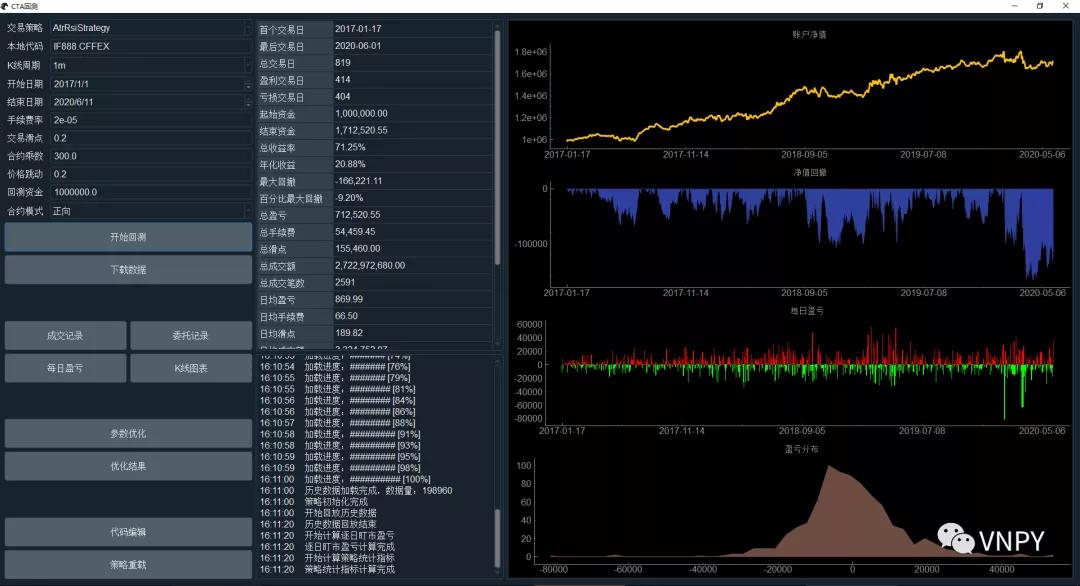
其中CtaBacktester采用了基于PyQt的图形界面,适合刚开始上手的初学者,十分简洁易用,点点鼠标就能快速完成【数据下载入库】和【历史数据回测】功能:
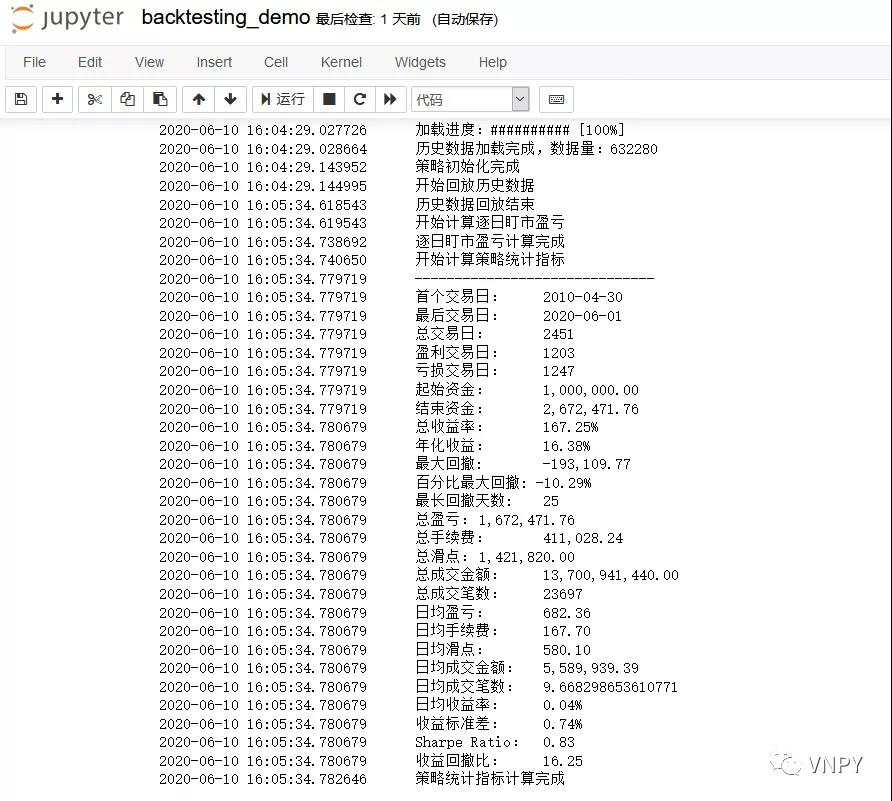
CtaStrategy回测引擎作为CtaBacktester图形界面背后的计算引擎,也可以在Jupyter Notebook中直接使用。在CLI命令交互的模式下,用户操作的自由度大大提升,可以实现更加复杂的分析脚本,如【策略组合回测】、【主力切换回测】、【滚动窗口优化】等等:
尽管功能更加强大,但截止目前最新版本(2.1.3.1),回测引擎基于Matplotlib和Seaborn实现的绘图展示却一直备受大家吐槽:
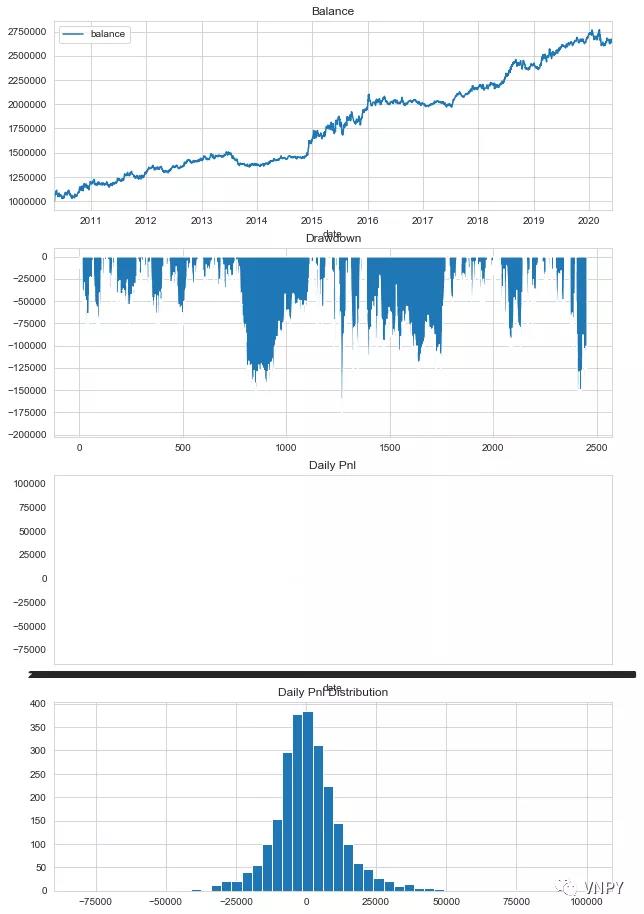
整体图表极端单调的白蓝配色,第三张每日盈亏子图一旦数据太多就会无法显示,底部X轴坐标密集成了黑色长条,除了能右键另存为图片外几乎毫无交互功能......妥妥体现出了我们vn.py钢铁直男团队的审美。
更好的选择
长期在社区论坛被这么吐槽下去也不是个事,好在Python大数据分析的生态比起六年前vn.py刚起步的时候早就今非昔比,做了点功课后快速选定了新的方向:Plotly。
仅看能绘制的图表类型,Plotly对比Matplotlib来说可能优势未必那么明显(仅限于vn.py应用范围),但在绘图性能和交互式功能方面,Plotly基于Javascript在浏览器中动态绘制的图表,就吊打Matplotlib的静态图片几条大街了。
下面我们就试着用Plotly在Jupyter Notebook中绘制出上面的策略统计图表,首先是安装plotly.py,打开cmd直接运行:
pip install plotly
然后启动Jupyter Notebook来运行历史数据回测,并获取到回测的统计结果数据,当然在运行前请先确保已经准备好了历史数据(没有的同学可以申请RQData试用下载:点击链接),代码如下:
# 加载相关模块
from datetime import datetime
from vnpy.app.cta_strategy.backtesting import BacktestingEngine, OptimizationSetting
from vnpy.app.cta_strategy.strategies.atr_rsi_strategy import AtrRsiStrateg
# 运行策略回测
engine = BacktestingEngine()
engine.set_parameters(
vt_symbol="IF888.CFFEX",
interval="1m",
start=datetime(2010, 1, 1),
end=datetime(2020, 7, 30),
rate=0.3/10000,
slippage=0.2,
size=300,
pricetick=0.2,
capital=1_000_000,
)
engine.add_strategy(AtrRsiStrategy, {})
# 统计分析结果
engine.load_data()
engine.run_backtesting()
df = engine.calculate_result()
engine.calculate_statistics()
到这里,我们已经准备好了绘图所需的全部数据,保存在一个pandas.DataFrame数据结构df中,下一步就可以开始尝试用Plotly来画图了,首先加载Plotly相关模块:
import plotly.graph_objects as go
from plotly.subplots import make_subplots
其中的go模块包含了Plotly中的绘图组件(折线图、柱状图、面积图、散点图等等),而make_subplots函数则用于创建带子图的绘图区域。真正的绘图代码则十分简单,只有短短几行:
# 创建一个4行、1列的带子图绘图区域,并分别给子图加上标题
fig = make_subplots(rows=4, cols=1, subplot_titles=["Balance", "Drawdown", "Daily Pnl", "Pnl Distribution"], vertical_spacing=0.06)
# 第一张:账户净值子图,用折线图来绘制
fig.add_trace(go.Line(x=df.index, y=df["balance"], name="Balance"), row=1, col=1)
# 第二张:最大回撤子图,用面积图来绘制
fig.add_trace(go.Scatter(x=df.index, y=df["drawdown"], fillcolor="red", fill='tozeroy', line={"width": 0.5, "color": "red"}, name="Drawdown"), row=2, col=1)
# 第三张:每日盈亏子图,用柱状图来绘制
fig.add_trace(go.Bar(y=df["net_pnl"], name="Daily Pnl"), row=3, col=1)
# 第四张:盈亏分布子图,用直方图来绘制
fig.add_trace(go.Histogram(x=df["net_pnl"], nbinsx=100, name="Days"), row=4, col=1)
# 把图表放大些,默认小了点
fig.update_layout(height=1000, width=1000)
# 将绘制完的图表,正式显示出来
fig.show()
不必经历Matplotlib绘图的漫长等待,几乎一瞬间,结果就显示了出来:
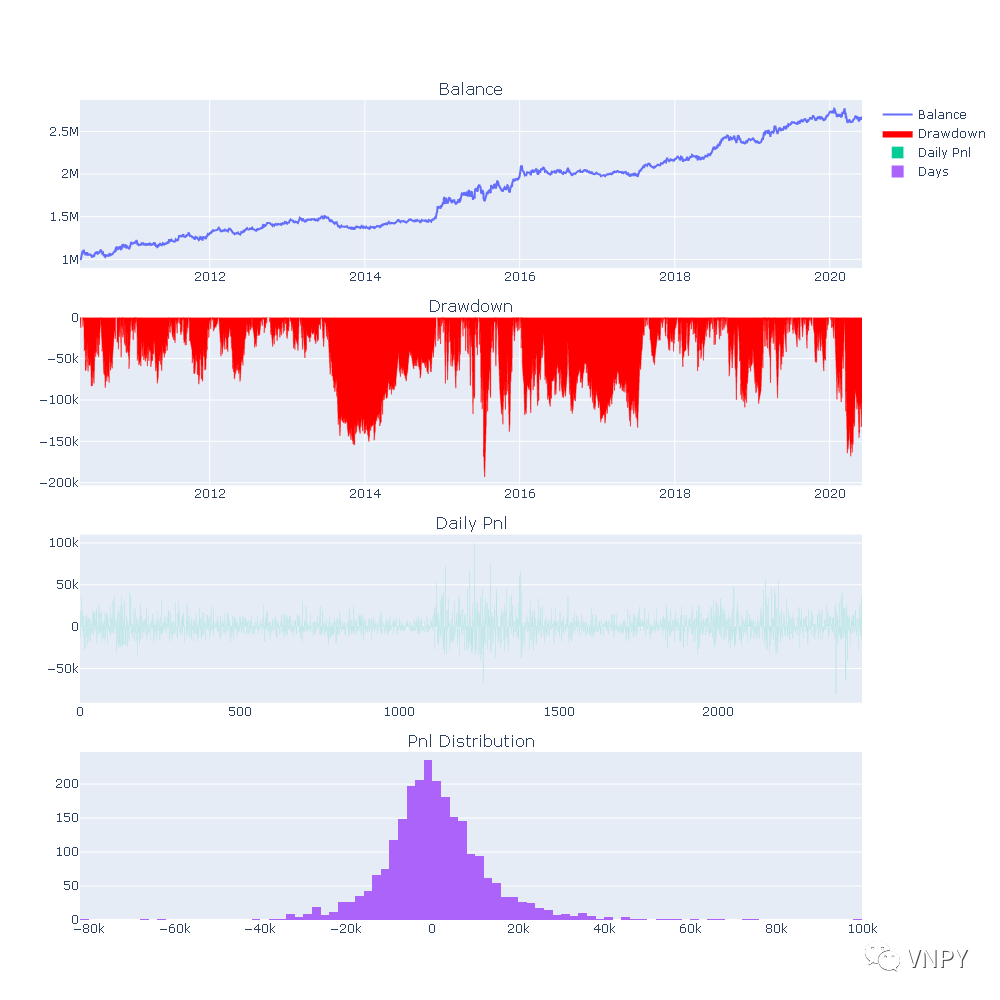
就算是钢铁直男也得承认,比起之前的Matplotlib图表,这个真的好看太多。
首先作为能偷懒一定要偷懒的优秀开发者,我们是绝对不会没事跑去设置颜色的,四张子图中除了面积图必须设底色不然不显示外,另外三张子图的显示都是默认自动选择的颜色和效果。
另外还有个优点在上述截图上没法体现,将鼠标移动到子图上任意位置时,会自动显示当前X轴位置对应的Y轴数据细节,连日期时间戳也完全清楚,再也不用把df给print出来后一行行去翻数据了。
3D参数曲面
有了这么个方便的图表工具后,接下来自然要更进一步发挥作用。参数优化是所有量化策略开发过程中极为重要的步骤,通过调整参数的数值实现策略模型对历史数据的最优匹配,来更好的把握未来实盘交易中的行情。
关于参数优化的数学原理、详细步骤、注意事项,足足可以写上一个系列的文章来讲解,在这里我们不去做额外的深入,先用这段代码快速跑出一个优化结果:
# 创建优化配置
setting = OptimizationSetting()
# 选择夏普比率作为目标函数
setting.set_target("sharpe_ratio")
# 选择优化rsi_length和atr_length两个参数
setting.add_parameter("rsi_length", 2, 11, 1)
setting.add_parameter("atr_length", 10, 30, 2)
# 通过多进程穷举算法来执行优化
result = engine.run_optimization(setting)
采用文本形式输出的结果如下:

或者在CtaBacktester组件中通过图形界面执行优化,也可以得到类似的显示:
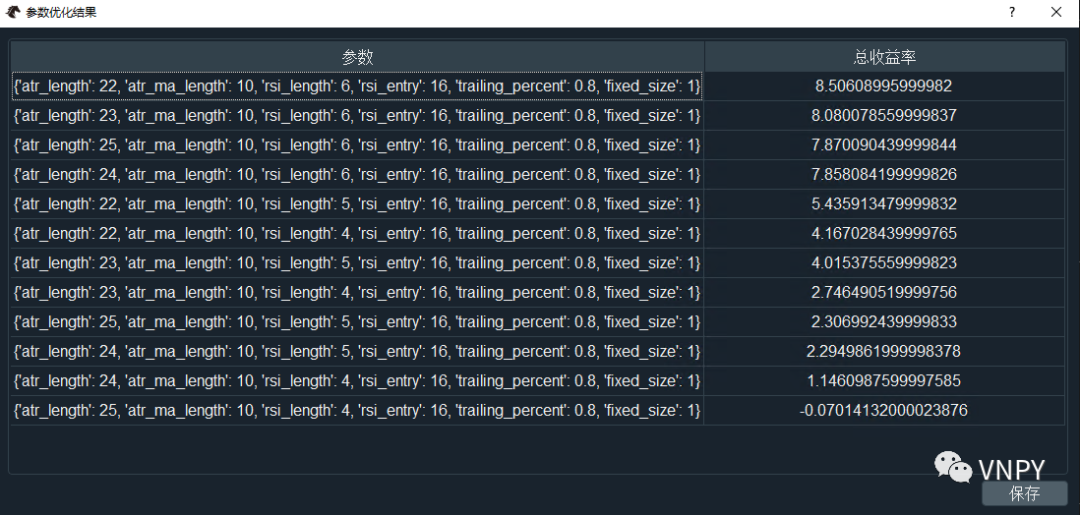
所有的参数组合,都已经根据目标函数的结果从高到低排列。比起单纯选择排在第一位的参数组合,有经验的同学会更加倾向于选择位于【参数平原】的结果,即其附近的结果都相对更好的组合。
尽管数字都已经显示出来了,但是对于我们人脑来说想要从其中找到这个平原,难度还是太大了点。更直观的方式还是通过图表来判断,2个自变量,1个因变量,正好可以组合为3D曲面。
首先是将上一步中保存下来的优化结果result列表中的数据,调整其格式生成X、Y、Z三条坐标轴上的数据点:
# 直接取出X、Y轴
x = setting.params["atr_length"]
y = setting.params["rsi_length"]
# 通过映射的方式取出Z轴
z_dict = {}
for param_str, target, statistics in result:
param = eval(param_str)
z_dict[(param["atr_length"], param["rsi_length"])] = target
z = []
for x_value in x:
z_buf = []
for y_value in y:
z_value = z_dict[(x_value, y_value)]
z_buf.append(z_value)
z.append(z_buf)
准备好了数据,又到了用上Plotly的时刻,简单的三行代码(update_layout中因为参数过长做了换行处理):
fig = go.Figure(data=[go.Surface(z=z, x=x, y=y)])
fig.update_layout(
title='优化结果', autosize=False,
width=600, height=600,
scene={
"xaxis": {"title": "atr_length"},
"yaxis": {"title": "rsi_length"},
"zaxis": {"title": setting.target_name},
},
margin={"l": 65, "r": 50, "b": 65, "t": 90}
)
fig.show()
同样几乎瞬间,就在Jupyter中看到了显示出来的参数优化结果的3D曲面图:
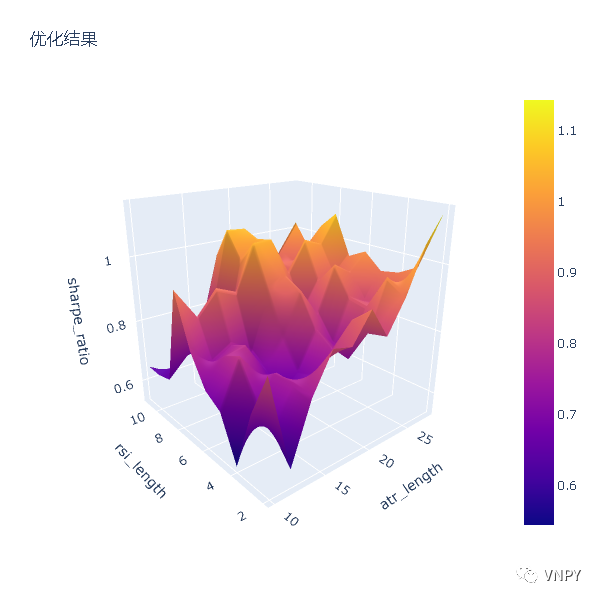
其中平面的X、Y轴分别显示的是两个参数rsi_length和atr_length,而垂直的Y轴则显示的优化目标sharpe_ratio的数值,三者共同构成了3D曲面图,同时【参数平原】也变得一目了然,真的就是选择曲面上“最高的平原区域”。
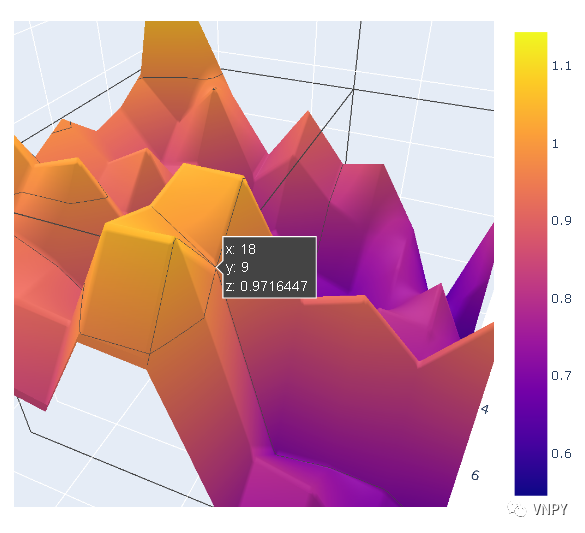
尽管截图中没法体现出来,该3D图表还可以非常方便的在三条轴线上进行360度旋转,以及拉近和拉远操作,并且当鼠标移动到曲面上时也可以直接看到该位置对应的具体数据内容,如下图所示:
最终的结论
也不多说啥了,接下来的v2.1.4版本让大家直接全都用上!
涨价通知
感谢vn.py社区用户的支持。
【vn.py全实战进阶 - CTA策略】课程销量已经达到778份。
销量超过800后将会进行一次涨价,涨价后的价格为499(目前是399)。
最后22份名额,感兴趣的朋友请抓紧时间吧。
购买请直接扫描下方二维码:

