

发布于vn.py社区公众号【vnpy-community】
原文作者: 丛子龙 | 发布时间:2023-09-19
2023年VeighNa小班特训营【套利价差交易】即将在10月中旬开班!对比趋势跟踪类的CTA策略,均值回归类的价差策略由于其高胜率的特征,能够实现相对更加平稳的盈利绩效,适合用于量化投资组合在市场横盘震荡期的配置优化。目前半数名额已经被报名锁定,感兴趣的同学请抓紧!内容大纲戳这里。
扩大ETF范围
本文将会在上一篇文章中提到的策略基础之上,扩大可投资的标的数量,在更多种类的大类资产中寻找超额收益。
我们从上市时间在2016年以前的ETF中选择了如下标的:
医药50ETF(512120.SSE)
金融ETF(510230.SSE)
TMTETF(512220.SSE)
信息科技ETF(512330.SSE)
证券保险ETF(512070.SSE)
可选消费ETF(159936.SZSE)
必选消费ETF(512600.SSE)
能源ETF(159930.SZSE)
材料ETF(159944.SZSE)
大宗商品ETF(510170.SSE)
黄金ETF(518880.SSE)
相信大家对A股市场中的行业轮动现象都不陌生。行业轮动是利用市场趋势获利的一种主动交易策略,其本质是利用不同投资品种强势时间的错位对行业持仓进行切换,以达到投资收益优化的目的。
通俗点讲,就是根据不同行业的区间表现差异性进行轮动配置,力求能够抓住区间内表现较好的行业、剔除表现不佳的行业,在判断市场不佳的时候,降低权益类仓位,提升另类资产的比例。
在本策略中,专门选择了能代表具体行业的ETF作为资产配置标的,上述列表中除了行业ETF之外还包括了大宗商品和黄金ETF。大宗商品具有较好的抗通胀属性,而黄金则是具有避险资产的属性。同时它们自身也与权益类资产一样,拥有较强的趋势性。
选定了资产池以后,下一步就是将数据加载到回测引擎中进行回测,策略层面将会沿用上篇文章中的EtfRotationStrategy。
这次在回测任务层面会与常用的单次回测稍有不同,原因是我们并不知道怎样配置资产组合才能获得更好的效果,所以在每次回测中需要尝试调整:
- 资产池中的ETF数量,可以使用到上述列表中所有的资产,也可以选择其中一半,抑或是三分之二;
- 每次轮动时,选择同时持有的ETF数量,以及对应在每只ETF上分配的资金。
为了尽可能寻找到优质的资产组合,本次投研将使用“嵌套循环+批量回测”的方法,具体实现包括以下三步:
第一步:确定组合搜索空间
第二步:遍历组合列表回测
第三步:对回测结果排序分析
投研代码实现
第一步:确定组合搜索空间
首先要计算的是:给定一定数量的合约,一共有多少种组合方法。在这里会用到Python的内置库【itertools】:
# 大类资产ETF范围
etf_list = [
"510170.SSE",
"159944.SZSE",
"512220.SSE",
"512120.SSE",
"159936.SZSE",
"159930.SZSE",
"512330.SSE",
"510230.SSE",
"512600.SSE",
"512070.SSE",
"518880.SSE",
]
# 筛选投资池,下限4只
all_combinations = []
for r in range(4, len(etf_list)):
all_combinations.extend(combinations(etf_list, r))
# 显示总投资池数量
len(all_combinations)
运行上述代码,即可得到一个缓存着所有可能组合的列表。
第二步:遍历组合列表回测
这么多组合,用手来一个一个敲入系统进行回测肯定是不现实的。随着标的池扩大,组合总数会以指数级增长。此时需要编写一段脚本让程序实现批量回测并缓存目标数据:
def run_backtesting(vt_symbols: list[str], holding_size: int) -> float:
"""运行回测并返回夏普比率"""
engine = BacktestingEngine()
engine.output = lambda a: a
engine.set_parameters(
vt_symbols=vt_symbols,
interval=Interval.DAILY,
start=datetime(2016, 1, 1),
end=datetime.now(),
rates={key: 0.0001 for key in vt_symbols},
slippages={key: 0.001 for key in vt_symbols},
sizes={key: 1 for key in vt_symbols},
priceticks={key: 0.001 for key in vt_symbols},
capital=1_000_000,
)
setting = {"holding_size": holding_size}
engine.add_strategy(EtfRotationStrategy, setting)
engine.load_data()
engine.run_backtesting()
engine.calculate_result()
statistics = engine.calculate_statistics(output=False)
return statistics["sharpe_ratio"]
# 遍历执行回测
results = {}
for combo in all_combinations:
vt_symbols = list(combo)
for i in range(1, math.floor(len(vt_symbols) / 2) + 1):
sharpe_ratio = run_backtesting(vt_symbols, i)
results[combo, i] = sharpe_ratio
运行完成后就会得到一个名为【results】的字典,字典当中包含每一个组合的夏普比率,下一步对results进行排序:
# 基于Sharpe Ratio排序
sorted_results = sorted(results, key=results.get, reverse=True)
# 查看排名前100的组合
print(sorted_results[:100])
第三步:对回测结果排序分析
首先需要查看在排名靠前的组合中哪些ETF出现的次数较多:
# 计算参数出现频次
etf_counts = defaultdict(int)
size_counts = defaultdict(int)
for tp in sorted_results[:100]:
vt_symbols, holding_size = tp
for vt_symbol in vt_symbols:
etf_counts[vt_symbol] +=1
size_counts[holding_size] += 1
# 绘制ETF代码的出现频率
plt.figure(figsize=(12, 6))
plt.bar(etf_counts.keys(), etf_counts.values()) ))
# 绘制持仓数量出现频率
plt.bar(size_counts.keys(), size_counts.values())
运行过后得到下图(为了阅读清晰,这里将ETF代码转换成了名称):

排名靠前的投资组合中,出现频率较高的有必选消费ETF,信息科技ETF,金融ETF和黄金ETF。这说明在回测时段中,能为策略提供较好收益的资产是它们。
同时不同资产出现频率的差别并没有非常显著,说明每一个资产都可以在不同的时间提供一定的超额收益。
另一方面,排名靠前的ETF持仓数量为2,其次是3和1:
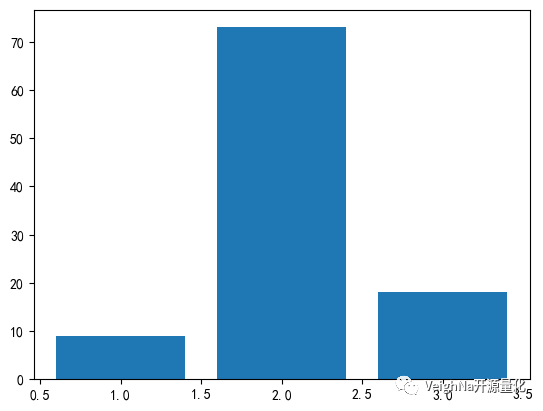
这显示并非同时持仓合约的数量越大效果就越好,反而将合约数量控制在一定水平以内可能获得更好的整体绩效。
策略历史回测
接下来使用排名靠前的ETF组合池作为回测合约,并用优化引擎对【regression_window】参数进行穷举优化,得到的结果如下:
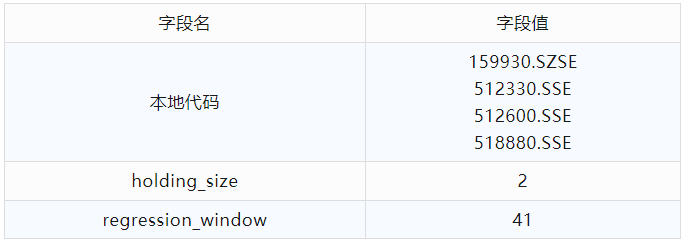
回测结果

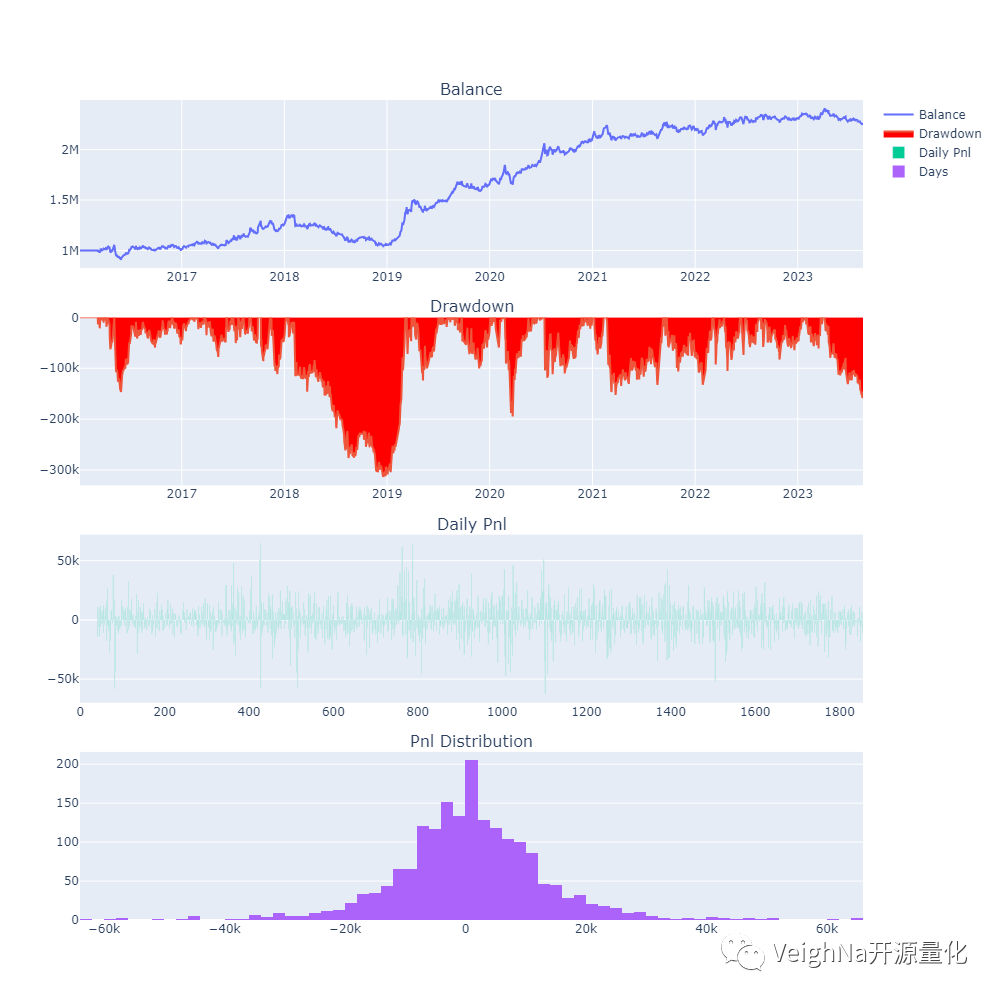
从资金曲线上看,虽然经过了前文的种种优化,但本次选择的ETF组合池整体回测绩效不如之前文章中的结果。
每日持仓
既然是轮动策略,那么理所当然会希望分析在历史回测过程中策略持仓成分的变化。这时可以遍历回测引擎的逐笔成交记录字典(engine.trades)来一笔笔检视每日持仓的变化,但无疑很麻烦,而且不够直观。
更方便的方法,是通过回测引擎提供的【get_all_daily_results】获取策略的逐日盯市统计数据来实现可视化分析:
import pandas as pd
import plotly.graph_objects as go
# 这里的实现需要运行完回测程序,并得到了一个engine对象
# 获取每日持仓数据
results = engine.get_all_daily_results()
# 创建DataFrame
df = pd.DataFrame(
[pos.end_poses for pos in results], index=[pos.date for pos in results]
)
# 这里对数据进行简单处理,我们假设所有持仓都是同等大小
df = df.clip(0, 100)
# 还记得持仓种类数额吗?这里将N设置为策略里的security_size
df[df.T.sum() > 100] *= 1 / 2
# 绘制图表
fig = go.Figure()
for col in df.columns:
fig.add_trace(
go.Scatter(x=df.index, y=df[col], mode="none", fill="tozeroy", name=col)
)
fig.show()
输出的历史持仓分布图表如下:
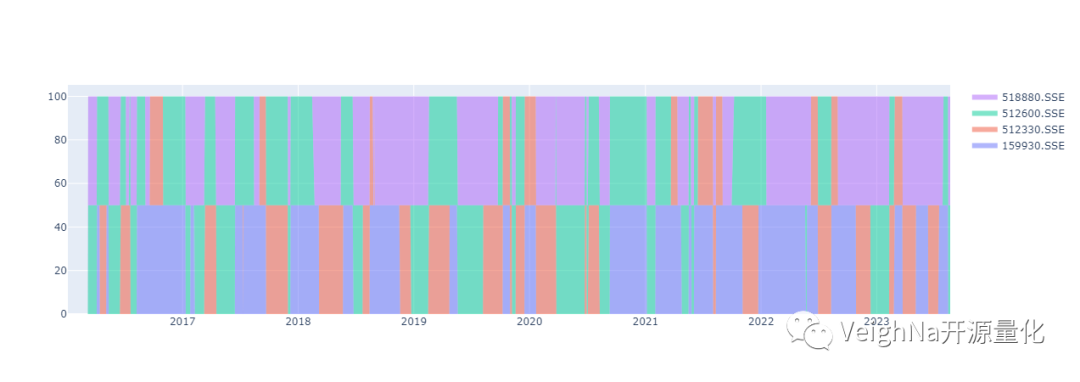
需要注意的是,上述绘图方法只适用于策略在每只ETF上持仓市值相同的情况。有兴趣的同学也可以自行调整大类资产ETF的范围,结合之前两篇文章介绍的优化方法进一步的研究。
完整策略代码和回测数据文件,可以通过【VeighNa进阶用户交流群】获取:

免责声明
文章中的信息或观点仅供参考,作者不对其准确性或完整性做出任何保证。读者应以其独立判断做出投资决策,作者不对因使用本报告的内容而引致的损失承担任何责任。
