from vnpy_ctastrategy import (
CtaTemplate,
StopOrder,
TickData,
BarData,
TradeData,
OrderData,
BarGenerator,
ArrayManager,
)
import talib
class MacdStrategy(CtaTemplate):
""""""
author = "alxbj"
macd = 0
signal = 0
hist = 0
roc = 0
fast_period = 12
slow_period = 26
signal_period = 9
#参数
parameters = [
"fast_period",
"slow_period",
"signal_period",
]
#变量
variables = [
"macd",
"signal",
"hist"
]
def __init__(self, cta_engine, strategy_name, vt_symbol, setting):
""""""
super().__init__(cta_engine, strategy_name, vt_symbol, setting)
self.bg = BarGenerator(self.on_bar)
self.am = ArrayManager()
def on_init(self):
"""
Callback when strategy is inited.
"""
self.write_log("策略初始化")
self.load_bar(10)
def on_start(self):
"""
Callback when strategy is started.
"""
self.write_log("策略启动")
def on_stop(self):
"""
Callback when strategy is stopped.
"""
self.write_log("策略停止")
def on_tick(self, tick: TickData):
"""
Callback of new tick data update.
"""
self.bg.update_tick(tick)
def on_bar(self, bar: BarData):
"""
Callback of new bar data update.
"""
self.cancel_all()
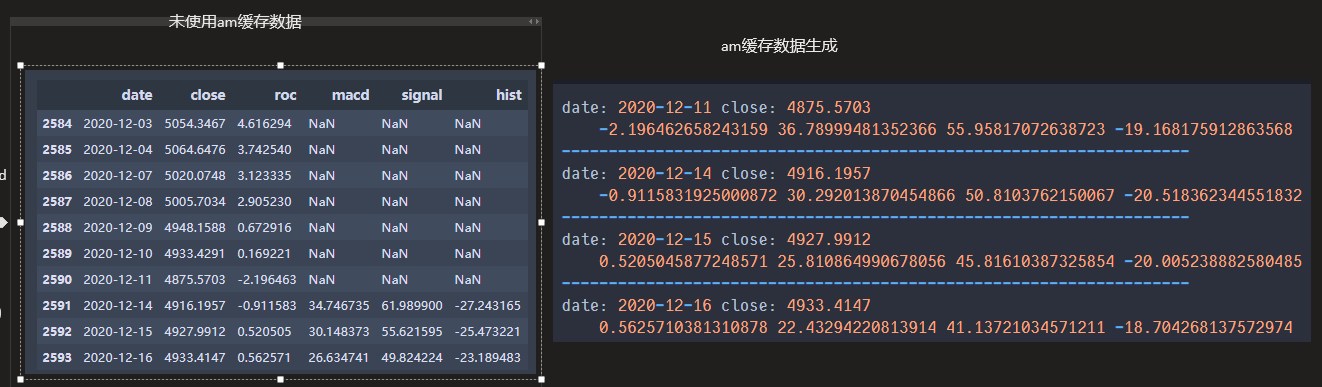
am = self.am
am.update_bar(bar)
if not am.inited:
return
# 用arraymanager内置的macd获取函数生成指标数据
self.macd,self.signal,self.hist = am.macd(
self.fast_period,
self.slow_period,
self.signal_period,
array=False)
self.roc = am.roc(14,array=False)
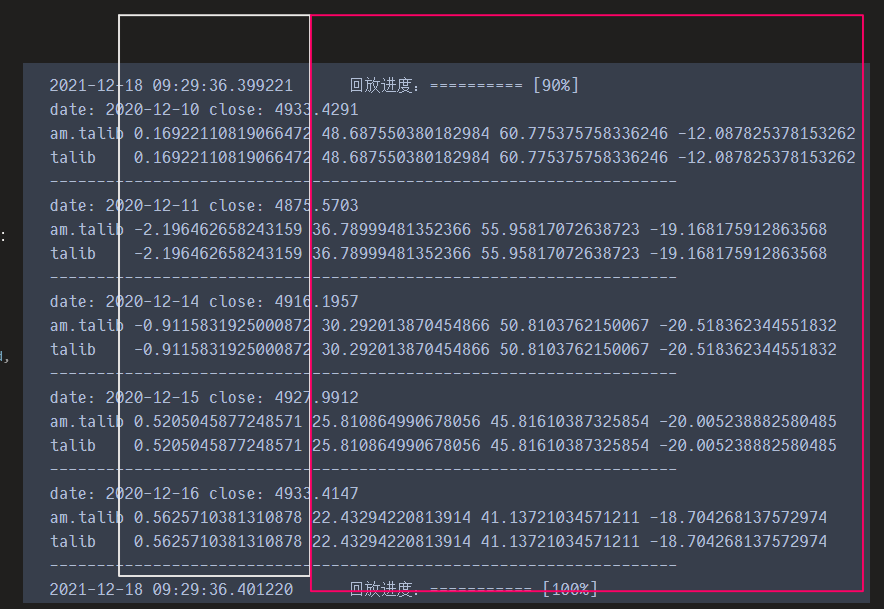
print('date:',bar.datetime.strftime( '%Y-%m-%d' ),
'close:',bar.close_price)
print('am.talib',self.roc,self.macd,self.signal,self.hist)
# 直接用talib获取macd指标数据
close = self.am.close_array
macd,signal,hist = talib.MACD(close, 12, 26, 9)
roc = talib.ROC(close,14)
print('talib ',roc[-1],macd[-1], signal[-1], hist[-1])
print('-------------------------------------------------------------------')
self.put_event()
def on_order(self, order: OrderData):
"""
Callback of new order data update.
"""
pass
def on_trade(self, trade: TradeData):
"""
Callback of new trade data update.
"""
self.put_event()
def on_stop_order(self, stop_order: StopOrder):
"""
Callback of stop order update.
"""
pass