

昨天再研究lru_cache缓存读取回测优化时候,使用了性能分析工具cProfile,发现还是非常强力的分析工具,这里做个简单介绍。并结合说下一些策略提速思路。
关于cProfile使用这个文章写的很详细,https://www.cnblogs.com/btchenguang/archive/2012/02/03/2337112.html 。 这里我简单接受下。
安装
不用安装,python一般自带都有的,
使用
使用方法有几个,我是直接输出。就是把回测代码放在一个方法里面,比如runBackTesting()里面。然后再main方法按照下面代码跑,这里是按照累计时间排序的。提示,最好注释掉Matplot图像输出,因为交互的时间也是统计的。
if __name__ == '__main__':
cProfile.run("runBackTesting()", sort="cumulative")性能分析结果
如下图所示
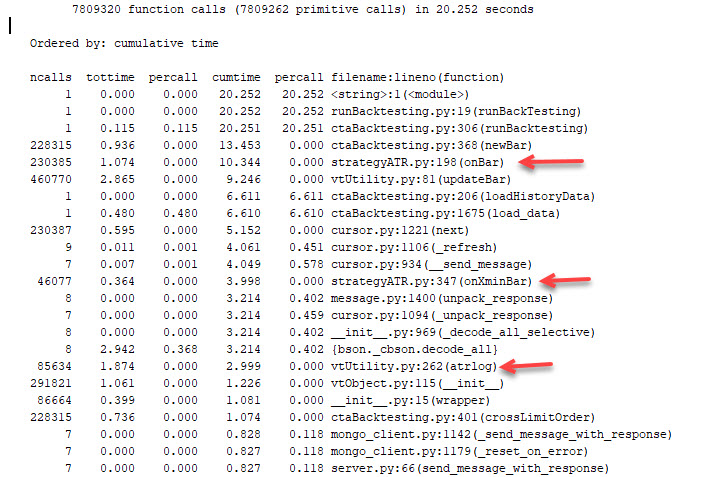
- 第一行 是总共调用function次数,和总运行时间次数
- 下面列的说明
- ncalls:表示函数调用的次数;
- tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
- percall:(第一个percall)等于 tottime/ncalls;
- cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
- percall:(第二个percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
- filename:lineno(function):每个函数调用的具体信息;前面是文件名,第几行,后面是方法名,有些方法比如max,min这些就没有文件名了。
一些分析
一般关注两个ncalls,和cumtime。这里结合说下一些提速思路
- 通常ncalls如果只有一两次,但是cumtime很长;这些通常是硬盘IO读取一类,只能尽量减少这些次数。
- ncalls次数很多,而且cumtime不低的,是优化重点,可以看到主要是bar回溯。如果vnpy自带改进思路不是很多。如果是自己的onBar方法,尽量减少里面运算,可以放在条件判断下的,先放进去。
比如self.pos == 0, self.pos <> 0: 这样。 - 在不会缺少数据的前提下,尽量减少ArrayManager中的长度,比如ArrayManager(50),比默认100少一半。
- 使用缓存或者固化数据,我自己定义了一个方法atrlog,发现用时很多,检查发现实在每次调用时候要用三次np.log去计算high, low, close的对数值;这里我索性一次过把所有历史数据在读取时候就把历史数据对数化放到cache里面。减少了耗时。
当然还有很多,只是一些我的思路,其他优化可以见专业文章。
