在lgb_model.py里:
data = df.select(df.columns[2: -1]).to_pandas()
在lstm_model.py里:
feature_data: np.ndarray = df.select(df.columns[2: -1]).to_numpy()
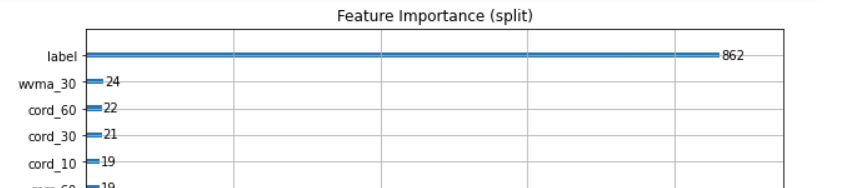
这句代码的目的是去除['datetime','symbol','label']这三列。
如果在AlphaDataset.prepare_data时,没有用到【合并结果数据因子特征】的话,'label'确实是最后一列,没有任何问题
一旦用了【合并结果数据因子特征】'label'不是最后一列。
fit的时候,就把label当成feature了
如果是我的理解有错,请指正,谢谢