
RPC服务端与客户端不在同一台机器上,有时候网络延迟稍大的时候,经常出现timeout。
当一次出现timeout后,后续任何请求响应模式的通信,都会出现如下错误:
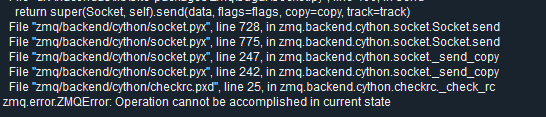
猜测是不是因为zmq的请求响应模式是严格一对一关系,出现一次timeout后,其请求序号再也对不上了。
查资料发现有种“懒海盗”模式,不知是否能够解决类似的问题呢?
“懒惰的海盗”(Lazy Pirate)模式:ZMQ 第四章 可靠的请求-应答模式

RPC服务端与客户端不在同一台机器上,有时候网络延迟稍大的时候,经常出现timeout。
当一次出现timeout后,后续任何请求响应模式的通信,都会出现如下错误:
猜测是不是因为zmq的请求响应模式是严格一对一关系,出现一次timeout后,其请求序号再也对不上了。
查资料发现有种“懒海盗”模式,不知是否能够解决类似的问题呢?
“懒惰的海盗”(Lazy Pirate)模式:ZMQ 第四章 可靠的请求-应答模式
按照我对客户端中重载的getattr的定义理解来说,
当dorpc执行超时的时候,执行的是:
if not n:
msg = f"Timeout of {timeout}ms reached for {req}"
raise RemoteException(msg)将引发RemoteException异常,从而导致下一行代码
rep = self.__socket_req.recv_pyobj()未能继续执行,从而破坏了客户端、服务端严格的一一对应的关系。
不知道对不对,另外该如何来处理呢?
自己up一下
可以自己改造下,RpcGateway和RpcService更多是对vnpy.rpc模块用法的DEMO,并不推荐直接实盘用
