看了stackoverflow的文章还有zmq的官方文档,因为水平有限,一知半解,摘抄出来探讨一下。
已知,zmq的socket是不能在多个线程之间共用的,可能会随机产生问题,使用锁、互斥似乎也不是好主意
虽然现在还不清楚随机崩溃的问题是否是因为线程共用socket引起的,但是目前的RpcSever代码似乎确实是存在共享socket的问题的。
引用如下(各段落摘抄自不同文章):
You MUST NOT share ØMQ sockets between threads. ØMQ sockets are not threadsafe. Technically it's possible to do this, but it demands semaphores, locks, or mutexes. This will make your application slow and fragile. The only place where it's remotely sane to share sockets between threads are in language bindings that need to do magic like garbage collection on sockets.
If you need to start more than one proxy in an application, for example, you will want to run each in their own thread. It is easy to make the error of creating the proxy frontend and backend sockets in one thread, and then passing the sockets to the proxy in another thread. This may appear to work at first but will fail randomly in real use.Remember: Do not use or close sockets except in the thread that created them.
You can create lots of 0MQ sockets, certainly as many as you have threads. If you create a socket in one thread, and use it in another, you must execute a full memory barrier between the two operations. Anything else will result in weird random failures in libzmq, as socket objects are not threadsafe.
If you’re sharing sockets across threads, don’t. It will lead to random weirdness, and crashes.
===================================================
官方多线程使用zmq的建议:
http://zguide.zeromq.org/page:all#Multithreading-with-ZeroMQ
范例代码:
http://zguide.zeromq.org/py:mtserver
===================================================
stackoverflow的一个回答
出处:https://stackoverflow.com/questions/5841896/0mq-how-to-use-zeromq-in-a-threadsafe-manner
There are a few conventional patterns, though I don't know how these map specifically to .NET:
- Create sockets in the threads that use them, period. Share contexts between threads that are tightly bound into one process, and create separate contents in threads that are not tightly bound. In the high-level C API (czmq) these are called attached and detached threads.
- Create a socket in a parent thread and pass at thread creation time to an attached thread. The thread creation call will execute a full memory barrier. From then on, use the socket only in the child thread. "use" means recv, send, setsockopt, getsockopt, and close.
- Create a socket in one thread, and use in another, executing your own full memory barrier between each use. This is extremely delicate and if you don't know what a "full memory barrier" is, you should not be doing this.
因为并不是这方面的专家,有些也是看得一知半解,所以根据上面的经验,抛出以下思路,想请问是否可行?
第1条思路:
不是很懂
第2条思路
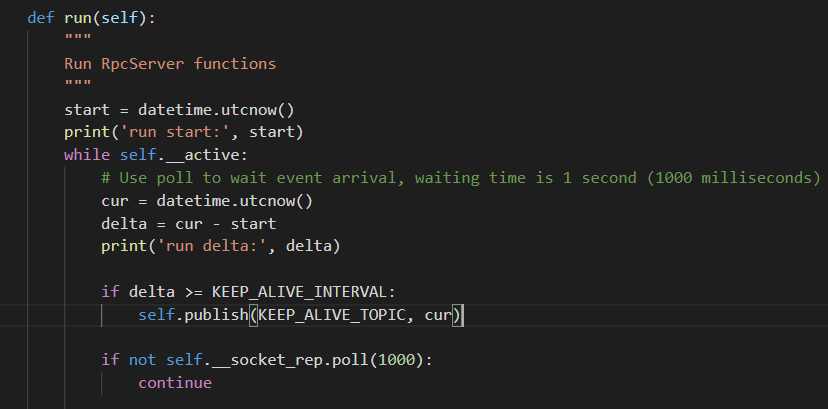
目前RpcSever的socket(zmq.REP)似乎是符合上面第二条的模式:即在父线程创建socket,在父进程创建子线程(这样可以形成一个内存屏障)。rep-socket只在这个子线程里面使用这个socket,但是socket(zmq.PUB)并不符合,因为这个socket不仅在RpcSever的子线程里面使用了,也在EventEngine的子线程里使用了,那能否把pub的socket全部移到RpcServer的子线程运行或者全部移到EventEngine的子线程内运行呢?
第3条思路
自己创建完全的内存屏障,似乎有点复杂。
另外推测的思路:
1、能否在RpcServer中的publish函数直接创建新的socket,比如with context.socket(zmq.PUB) as socket:,但是这样应该会频繁创建销毁socket,对性能是否会有很大的影响?
2、用Context().instance()创建全局上下文,能否在publish心跳的进程中使用一个固定的pub-socket,然后在publish交易事件中使用另外一个pub-socket?