

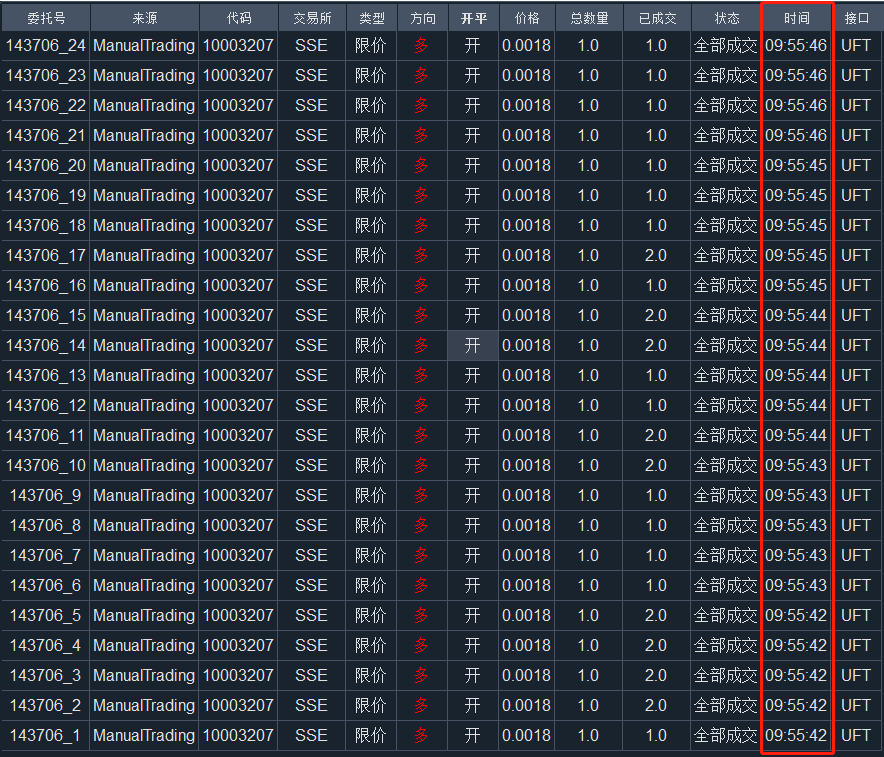
使用uft交易接口进行委托,成交后,发现回报记录里面成交数量大于总数量。如图:
找到对应的成交回报处理代码,发现部分代码如下:
def update_trade(self, data: dict) -> None:
""""""
symbol = data["InstrumentID"]
exchange = EXCHANGE_UFT2VT[data["ExchangeID"]]
sessionid = data["SessionID"]
order_ref = data["OrderRef"]
orderid = f"{sessionid}_{order_ref}"
order = self.orders.get(orderid, None)
if order:
order.traded += data["TradeVolume"]
if order.traded < order.volume:
order.status = Status.PARTTRADED
else:
order.status = Status.ALLTRADED
self.gateway.on_order(order)
trade_time = generate_time(data["TradeTime"])
timestamp = f"{data['TradingDay']} {trade_time}"
dt = datetime.strptime(timestamp, "%Y%m%d %H:%M:%S")
dt = CHINA_TZ.localize(dt)其中,if order片段的逻辑个人理解为——收到成交回报时,如果找到对应的委托回报记录,则将其已成交数据累加当前成交回报记录中的成交数量,并在更新对应状态后执行回调。
当时进行别的测试,每笔委托就下1手,然后短时间下了24笔。
通过打印发现:如果收到成交回报后还收到对应的委托回报,那么就会将数据覆盖,进而呈现正确的数据;
但如果成交回报是最后收到的(指该笔委托),那么对应的委托回报的数据就会错误。
对比ctp接口,是没有这段代码的,不清楚为什么此处要加上,是为了处理什么东西吗?
那带来的上述图中的错误又怎么办?
比如,我下10手,然后部分成交情况下,很可能导致显示全部成交,这个时候就不能进行撤单操作了
