xiaohe wrote:
是的,是根据CPU核心数量跑的。
请用htop看吧。
“是的 ” 是指本次更新(2.4.0)确实 会导致大部分被分配的cpu 闲置?
使用 htop 或 top 在解决 “导致大部分被分配的cpu 闲置” 这个问题上 能起到什么帮助呢? 还是需要观察其他的 资源使用情况?

xiaohe wrote:
是的,是根据CPU核心数量跑的。
请用htop看吧。
“是的 ” 是指本次更新(2.4.0)确实 会导致大部分被分配的cpu 闲置?
使用 htop 或 top 在解决 “导致大部分被分配的cpu 闲置” 这个问题上 能起到什么帮助呢? 还是需要观察其他的 资源使用情况?
potatoTaunt wrote:
xiaohe wrote:
是的,是根据CPU核心数量跑的。
请用htop看吧。“是的 ” 是指本次更新(2.4.0)确实 会导致大部分被分配的cpu 闲置?
使用 htop 或 top 在解决 “导致大部分被分配的cpu 闲置” 这个问题上 能起到什么帮助呢? 还是需要观察其他的 资源使用情况?
是的是指,是根据CPU核心数量跑的。
你这显示的是进程,而不是核心吧。
htop监控功能更强。
yy1588133 wrote:
xiaohe wrote:
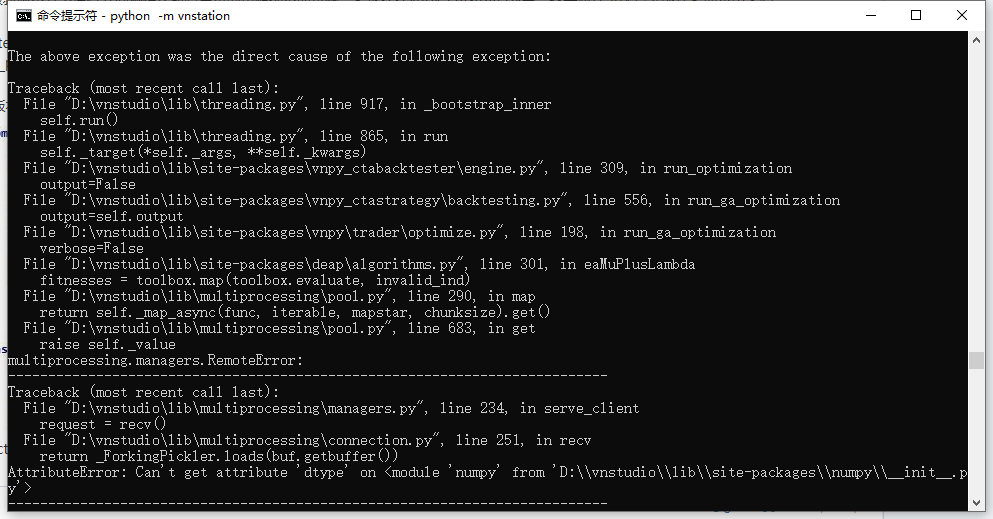
下面那张图看不清楚,好像有attributeerror报错,复制报错信息在网上搜索一下解决方法应该就行了
遗传算法优化时报错误,网上搜索无果
可以看一下是否跑示例策略也是报这个错,如果也是的话,那么可能是你自建的文件名模块名或者函数名冲突了。
可参考https://blog.csdn.net/marchcma/article/details/79596896?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7Eessearch%7Evector-8.essearch_pc_relevant&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7Eessearch%7Evector-8.essearch_pc_relevant
https://blog.csdn.net/kaever/article/details/105115288
xiaohe wrote:
potatoTaunt wrote:
xiaohe wrote:
是的,是根据CPU核心数量跑的。
请用htop看吧。“是的 ” 是指本次更新(2.4.0)确实 会导致大部分被分配的cpu 闲置?
使用 htop 或 top 在解决 “导致大部分被分配的cpu 闲置” 这个问题上 能起到什么帮助呢? 还是需要观察其他的 资源使用情况?
是的是指,是根据CPU核心数量跑的。
你这显示的是进程,而不是核心吧。
htop监控功能更强。
oh~,理解你的意思了。 最后实验发现,如果数据量比较大,并行优化有一个尴尬的点: 由于优化的时候会每组 setting 参数从Database (即硬盘)读取数据,运行速度会极大地被拖慢。 可是如果将数据保存在主进程中, 优化时直接对 history_data 赋值 又会有 进程间数据传输堵塞的问题, 致使被分配的cpu 资源利用不全。 不知道你对这个情况有没有什么建议?
如果数据量比较大可以换个快一点的数据库试试
xiaohe wrote:
如果数据量比较大可以换个快一点的数据库试试
haha
可参考26楼
请问portfolio strategy使用ga和bf optimization的时候,都是运行结束了才打印结果,有什么办法可以显示进度条吗,看优化完成了多少,不然一直等待响应也不知道要跑多久。谢谢!
在VeighNa的PortfolioStrategy模块中,使用遗传算法(GA)和暴力穷举(BF)优化时,默认情况下确实是在优化结束后才打印结果。不过,你可以通过以下方式来实现进度条的显示:
在run_bf_optimization函数中,已经使用了tqdm库来显示进度条。如果你没有看到进度条,可能是因为tqdm库未正确安装或配置。你可以通过以下步骤确保进度条正常显示:
确保安装了tqdm库:
pip install tqdm
在优化代码中,tqdm会自动显示进度条。如果你仍然看不到进度条,可以检查是否在优化函数中正确使用了tqdm。
遗传算法的进度条显示需要手动实现。你可以通过以下方式在遗传算法优化中添加进度条:
在run_ga_optimization函数中,添加tqdm来跟踪每一代的优化进度:
from tqdm import tqdm
def run_ga_optimization(...):
...
with tqdm(total=ngen, desc="遗传算法优化进度") as pbar:
for gen in range(ngen):
# 执行遗传算法优化逻辑
...
pbar.update(1)
如果你需要更灵活的控制,可以自定义进度条。例如,使用logging模块或print函数来定期输出优化进度:
def run_ga_optimization(...):
...
for gen in range(ngen):
# 执行遗传算法优化逻辑
...
print(f"优化进度: {gen + 1}/{ngen}")
通过以上方法,你可以在优化过程中实时查看进度,避免长时间等待。