

之前试过aksahre或者自己写爬虫爬取数据,数据获取耗时久且不稳定,主要是脚本维护不容易,这里推荐一个相对容易且免费的方式
先打开ricequant的投资研究板块,进入jupyter notebook,开启一个新的,先获取期货市场所有的上市合约字段头,然后使用get_price获取想要时段的数据
示例 2010-2024-5-31的日频数据,保存,然后退出点击下载即可获得数据
get_info = all_instruments(type='Future')
test_df = get_price(get_info['order_book_id'], start_date='2010-01-01', end_date='2024-05-31', frequency='1d', fields=None, adjust_type='pre', skip_suspended =False, market='cn', expect_df=True,time_slice=None)
test_df.to_csv('daily_bar.csv')
之后再在本地开个jupyter,使用pandas打开daily_bar.csv
from vnpy.trader.constant import (Exchange, Interval)
import pandas as pd
from vnpy.trader.database import get_database
from vnpy.trader.object import (BarData,TickData)
from datetime import datetime
from pytz import timezone
import json
database_manager = get_database()
tz = timezone( "Asia/Shanghai")
f = open('code_info.json','r')
content = f.read()
json_file = json.loads(content)
f.close()
def move_df_to_mongodb(imported_data:pd.DataFrame,collection_name:str,interval='d'):
bars = []
start = None
count = 0
interval = Interval(interval)
if '88' in collection_name:
exchange_code = (collection_name.split('88')[0]).upper()
elif '99' in collection_name:
exchange_code = (collection_name.split('99')[0]).upper()
else:
exchange_code = (collection_name[:-4]).upper()
try:
code_exchange = Exchange(json_file[exchange_code]['exchange'])
except:
print(f'合约{exchange_code} 无法查询到交易所代码,请查看json文件或合约信息')
return
for row in imported_data.itertuples():
# print(interval)
bar = BarData(
symbol=row.symbol,
exchange=code_exchange,
datetime=tz.localize(datetime.fromisoformat(row.datetime)),
#datetime=row.datetime.replace(tzinfo=utc_8),
interval=interval,
volume=row.volume,
open_price=row.open,
high_price=row.high,
low_price=row.low,
close_price=row.close,
open_interest=row.open_interest,
turnover=row.total_turnover,
gateway_name = 'DB'
)
bars.append(bar)
# do some statistics
count += 1
if not start:
start = bar.datetime
end = bar.datetime
# insert into database
database_manager.save_bar_data(bars)
print(f"Insert Bar {collection_name}: {count} from {start} - {end}")
def load_ricequant_df(rice_df):
daily_grups = rice_df.groupby('order_book_id')
code_ls = daily_grups.groups.keys()
for codex in code_ls:
load_df = daily_grups.get_group(codex).copy()
load_df = load_df[['order_book_id','date','open','high','low','close','volume','total_turnover','open_interest']]
load_df.columns = ['symbol','datetime','open','high','low','close','volume','total_turnover','open_interest']
load_df.symbol = load_df.symbol.str.lower()
print(f'开始导入 {codex} 行情')
move_df_to_mongodb(load_df,collection_name=codex)
daily_df = pd.read_csv('daily_bar.csv')
load_ricequant_df(daily_df)
文件链接:
链接:https://pan.baidu.com/s/1dylBHApYsyLDoIjeLM_UVA?pwd=rxa7
提取码:rxa7
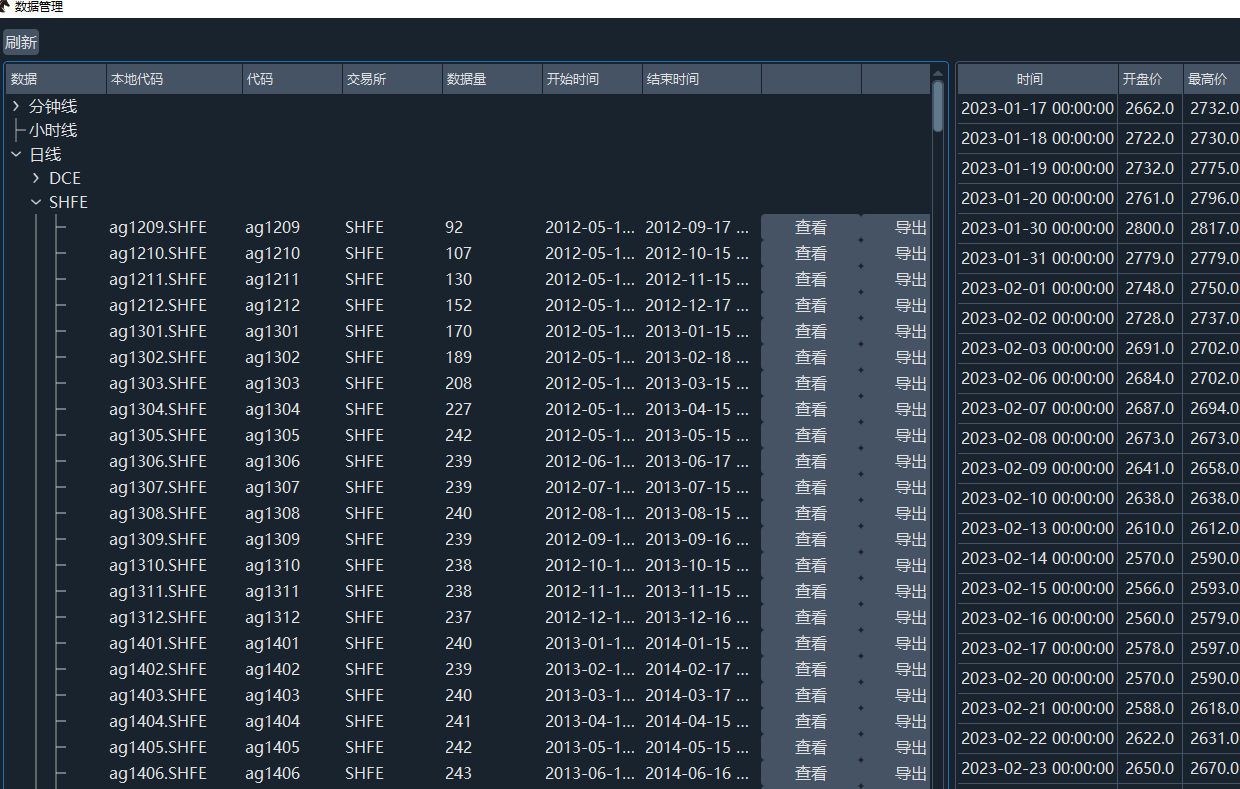
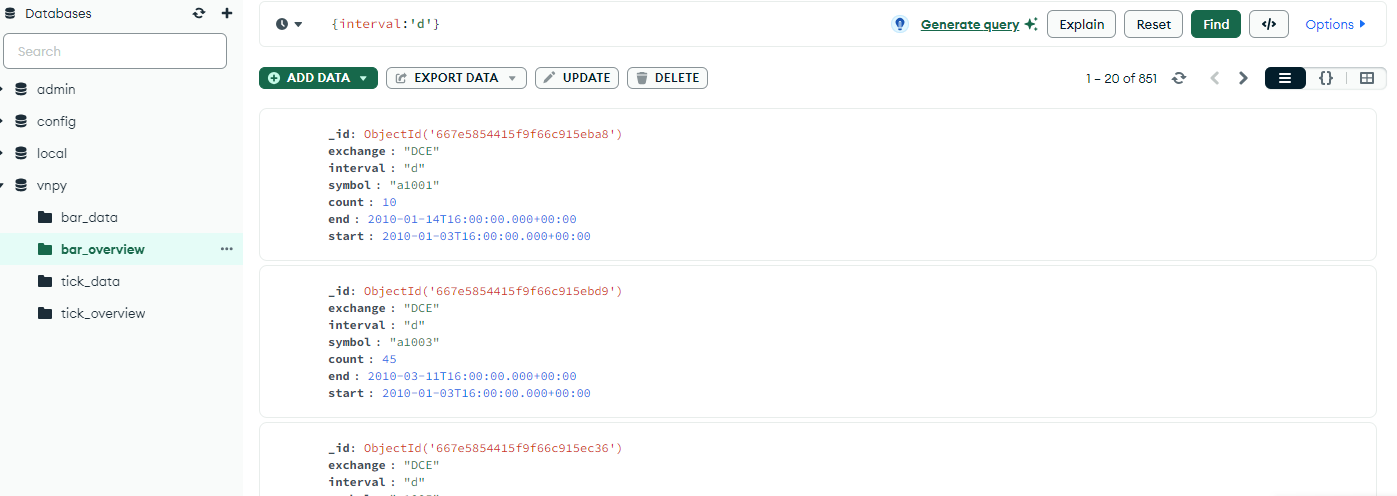
PS:
理论上也能从ricequant中获取分钟k然后再导入进vnpy数据库,代码构造类似。我没有尝试过(据估算分钟数据大约有30g,这可能需要按品种一个一个搬)。后面有时间探讨分钟k数据和更新方式。
PPS:
数据导入方式参考:
https://www.vnpy.com/forum/topic/3759-vn-pyshe-qu-jing-xuan-22-kan-wan-zhe-pian-che-di-xue-hui-csvli-shi-shu-ju-dao-ru?page=1
https://www.vnpy.com/forum/topic/3203-bian-xie-pythonjiao-ben-shi-xian-shu-ju-ru-ku

