

经过一段时间学习和实践,感觉对于期货择时交易,跟随趋势基本上可以被认为是不二途径。那么对于CTA交易策略来说,及早发现趋势是非常重要。寻找趋势的方法很多,经典的比如均线快慢线交叉,布林带还有其他各种时序动量指标,这里推荐看看公众号刀疤连的一边大作‘和趋势做纯纯的朋友’,有非常全面分析。
在实践中,发现经常陷入一个两难局面,一方面是希望及时发现趋势,这样不可避免就是的判定阈值变得敏感;往往就是敏感的指标被市场白噪声和某些蓄意大宝剑图形(针对趋势交易者的迅速拉升然后砸下来图形)触发,被来回打脸,连续亏损。另一个方面为了避免被来回打脸,调高触发指标,又会导致错失趋势。
之前一直尝试用流水线质检的方法去寻找趋势策略, 和分析时序序列有点相似。质检时候,要及时发现产出是否有生产线问题,如果晚了,大量残次品出来;如果太敏感,把个体随机问题认为是生产问题,又会因为生产线停机检修造成损失。之前用的CUSUM就是这个方法。
最近有一个思路,尝试用T 检验这个方法去发现趋势。关于T 检验现在也广泛用在质量检测,药效测试。这里面还有个典故,T检验是戈斯特为了观测酿酒质量而发明的。戈斯特在位于都柏林的健力士酿酒厂担任统计学家。戈斯特于1908年在Biometrika上公布T检验,但因其老板认为其为商业机密而被迫使用笔名(学生),所以有时候也叫学生检验。
这里不准备讲解具体检验数学逻辑,具体可以搜索之,这里只是说说应用;因为也是边学边用,有错漏这出。
T检验有三种主要类型:
1.独立样本t检验:比较两组独立样本平均值的方法,这里要求两组样本 方差相等,即具有方差齐性。
2.配对样本t检验:比较同一组中不同时间(例如,相隔一年)平均值的方法。
3.单一样本t检验:检验单个组的平均值对照一个已知的平均值。
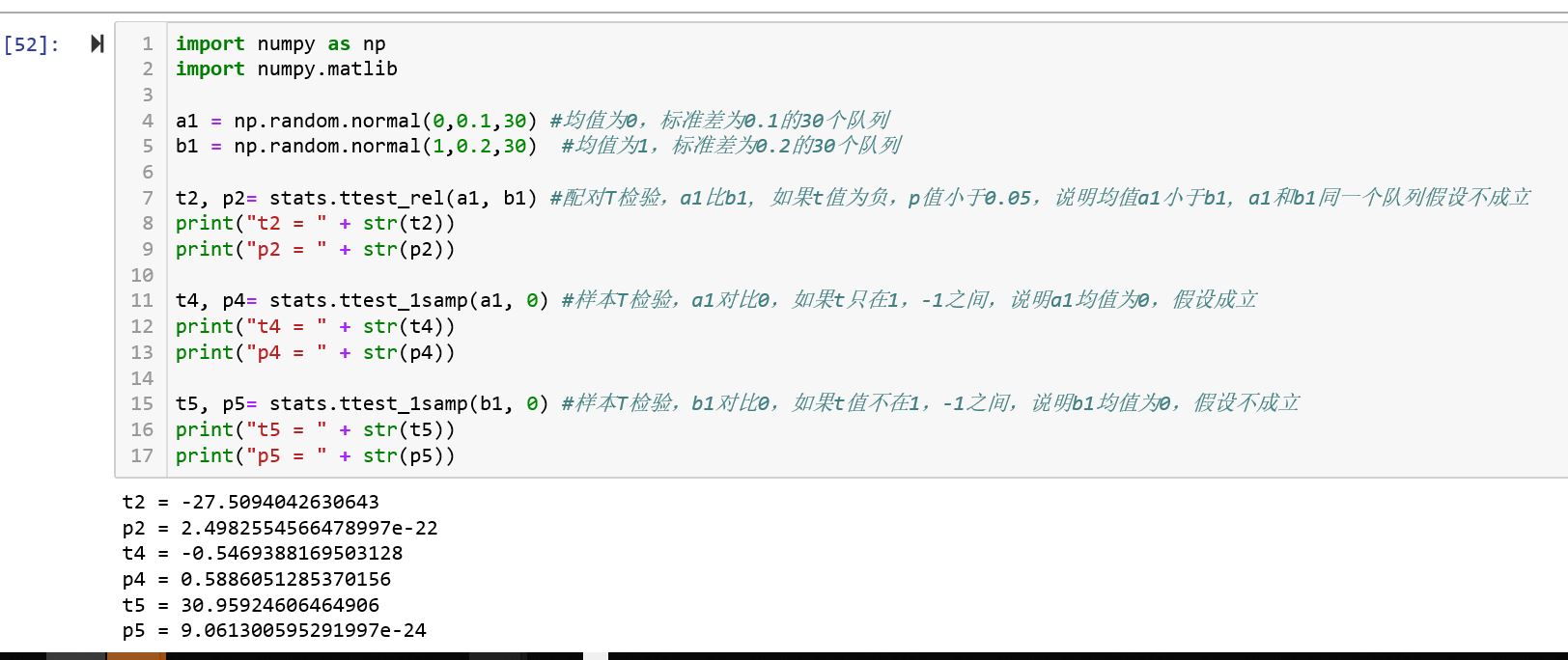
python的库stats已经提供T检验,就是stats.ttest_ind/ stats.ttest_rel/ stats.test_1samp 方法, 示例代码如下:
import numpy as np
import numpy.matlib
a1 = np.random.normal(0,0.1,30) #均值为0,标准差为0.1的30个队列
b1 = np.random.normal(1,0.2,30) #均值为1,标准差为0.2的30个队列
t2, p2= stats.ttest_rel(a1, b1) #配对T检验,a1比b1,如果t值为负,p值小于0.05,说明均值a1小于b1,a1和b1同一个队列假设不成立
print("t2 = " + str(t2))
print("p2 = " + str(p2))
t4, p4= stats.ttest_1samp(a1, 0) #样本T检验,a1对比0,如果t只在1,-1之间,说明a1均值为0,假设成立
print("t4 = " + str(t4))
print("p4 = " + str(p4))
t5, p5= stats.ttest_1samp(b1, 0) #样本T检验,b1对比0,如果t值不在1,-1之间,说明b1均值为0,假设不成立
print("t5 = " + str(t5))
print("p5 = " + str(p5))这里生成两个正态分布队列,方法很简单,返回T值,和P值;T值越接近0,则可认为假设可成立,如果T值离0值越远,比如[1,-1]之外,则假设不成立,正均值想上,小于0均值向下。
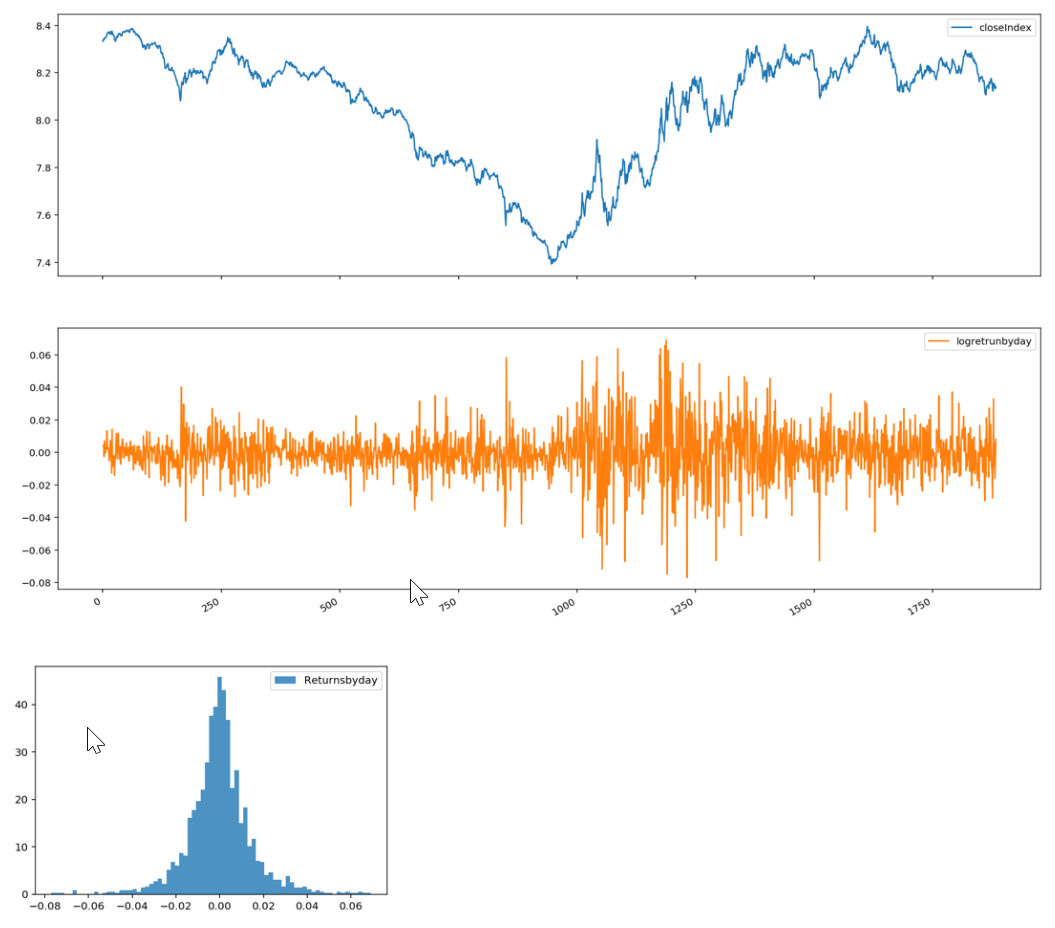
这里还有个前提,就是样本是来自正态分布总体的随机样本。而我们日常所用的期货价格分布并不是正态分布,就像CUSUM里面用的,这里使用时段(5分钟)的对数收益率,显示为近似正态分布,均值近似为0。可以考虑是否去极值,就是计算出标准差,然后将其中大于 u+3σ 的置换为u+3σ,将小于u-3σ 的置换为u-3σ,消除跳开的冲击。
下图为示意图,从close转为对数收益率,和对数收益率分布。
在CTA趋势发现时候, 这里使用主要是 配对样本t检验和单一样本t检验。
配对样本t检验:是按照时段进行对比,这里可以有相互部分覆盖的时段序列对比,比如 [t-30, t-10]和[t-20,t]对比,中间可以有10个时段相互覆盖。如果前后两个时间队列的T检验发现T值为正且大于1则,相对过往时段有趋势向上;反正向下。
单一样本t检验,用一段时间段和均值0对比,如果值在[-1.1]之间,可以认为其实没有趋势,如果大于1或者小于-1,则可以认为有向上或向下趋势。
下面简单代码示例, 是用5分钟对数收益率进行配对和样本T检测,如果连续3个配对样本的T值都大于1,或都小于-1,则去向上或向下。
dfrb5min['close']是一个close array,需要自己提前定义。
from scipy import stats
from scipy.stats import norm,t
import matplotlib.pyplot as plt
logdata = pd.DataFrame()
logdata['close'] = np.log(dfrb5min['close']) # 对数化传入5分钟close队列dfrb5min['close']
logdata['closeIndexDiff_1'] = logdata['close'].diff() # 1阶差分处理,求出对数收益率
t = 40
for i in range(t,len(logdata['close'])):
#求出配对T检测t4
t4, p4= stats.ttest_rel(logdata['closeIndexDiff_1'][i-20+1:i+1],logdata['closeIndexDiff_1'][i-30+1:i-10+1])
#求出样本T检测p0
t0, p0 = stats.ttest_1samp(logdata['closeIndexDiff_1'][i-15+1:i+1],0)
logdata.loc[i,'t'] = t4
logdata.loc[i,'t1samp'] = t0
#如果绝对值大于0,则使用
if abs(t0) > 1.0:
logdata.loc[i,'t0Index'] = t0
else:
logdata.loc[i,'t0Index'] = 0
if abs(t4) > 1.0:
logdata.loc[i,'tIndex'] = t4
else:
logdata.loc[i,'tIndex'] = 0
#csv输出
logdata.to_csv("C:\\Project\\MA8888va1min5v3.csv", index=True, header=True)
closeArray = np.array(dfrb5min['close'])
listup,listdown = [],[]
for i in range(1,len(logdata['closeO'])):
if logdata.loc[i-1,'tIndex'] >1 and logdata.loc[i,'tIndex']>1 and logdata.loc[i-1,'t0Index'] >1 and logdata.loc[i,'t0Index']>1 and logdata.loc[i-2,'tIndex']>1 and logdata.loc[i-2,'t0Index'] >1 :
listup.append(i)
elif (logdata.loc[i,'tIndex'] < -1 and logdata.loc[i-1,'tIndex'] <-1) and (logdata.loc[i,'t0Index'] < -1 and logdata.loc[i-1,'t0Index'] <-1) and logdata.loc[i-2,'tIndex']<-1 and logdata.loc[i-2,'t0Index'] <-1 :
listdown.append(i)
fig=plt.figure(figsize=(18,6))
plt.plot(closeArray, color='y', lw=2.)
plt.plot(closeArray, '^', markersize=5, color='r', label='UP signal', markevery=listup)
plt.plot(closeArray, 'v', markersize=5, color='g', label='DOWN signal', markevery=listdown)
plt.legend()
plt.show()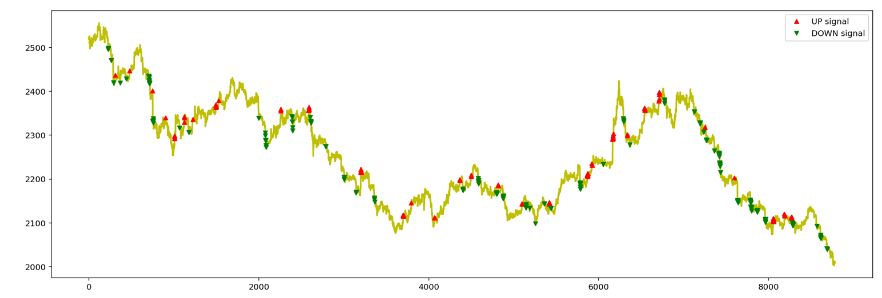
从示例图来看,有一定趋势发现能力,但是还是陷入短趋势困境,这个是时序队列长度选取,t值都有关系,还是要进一步优化。
